
Toni Lopez
Co-Founder at Karumi
·
Artificial intelligence is undergoing a paradigm shift. For years, the dominant logic was "bigger = better": models with hundreds of billions of parameters (frontier LLMs) trying to be good at everything. And yes, they achieved impressive things in general conversation and reasoning. But the focus has changed. It's no longer just about answering questions, it's about building agentic systems: autonomous AIs that plan, call APIs, execute code, handle structured data, and make chained decisions. In that context, massive models turn out to be expensive, slow, and over-engineered.
This blog post argues that Small Language Models (under 12B parameters) and Medium Language Models (from 13B to 70B parameters) aren't just good enough for agentic tasks, with the right training and different techniques, they can actually outperform the bigger ones. In future posts, we will focus on and dissect every innovation part and explain it in simple terms for everyone. Our post today is to show how and why small and medium language models are going to be the next hit in the industry.
1. Economics and Operational Efficiency
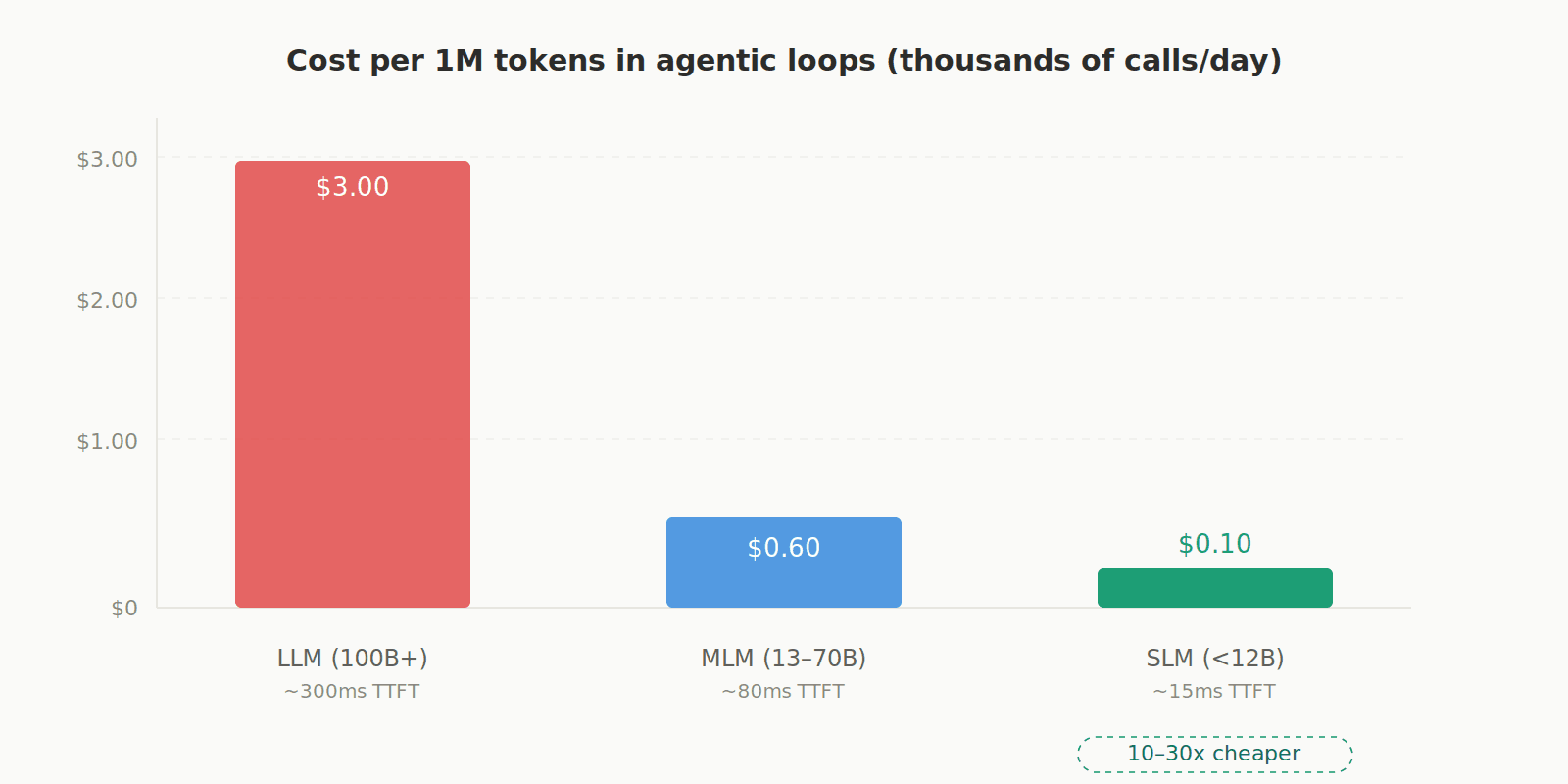
Agentic systems don't just make a single query, they execute thousands of calls in tight loops. Using a 100B+ parameter model for that is like using a Formula 1 car to do grocery shopping. SLMs are 10 to 30 times cheaper per token, have minimal latency (much lower time-to-first-token), and can run even on CPUs or mobile devices. This also enables edge deployment: running AI locally without depending on the cloud, which solves privacy, data sovereignty, and latency issues.
2. Agentic Skills Don't Require Massive Scale
The reality is, you don't really need the agentic model to write poems, stories, etc. What an agent needs, in a few words, is: correct function calling, valid JSON generation, strict schema adherence, and the possibility to have code execution. With SLMs, nowadays you can perfectly generate formatted outputs; examples that I found are using constrained decoding techniques (XGrammar or Outlines are libraries that offer different techniques like the mentioned one), allowing SLMs to close the gap with frontier models.
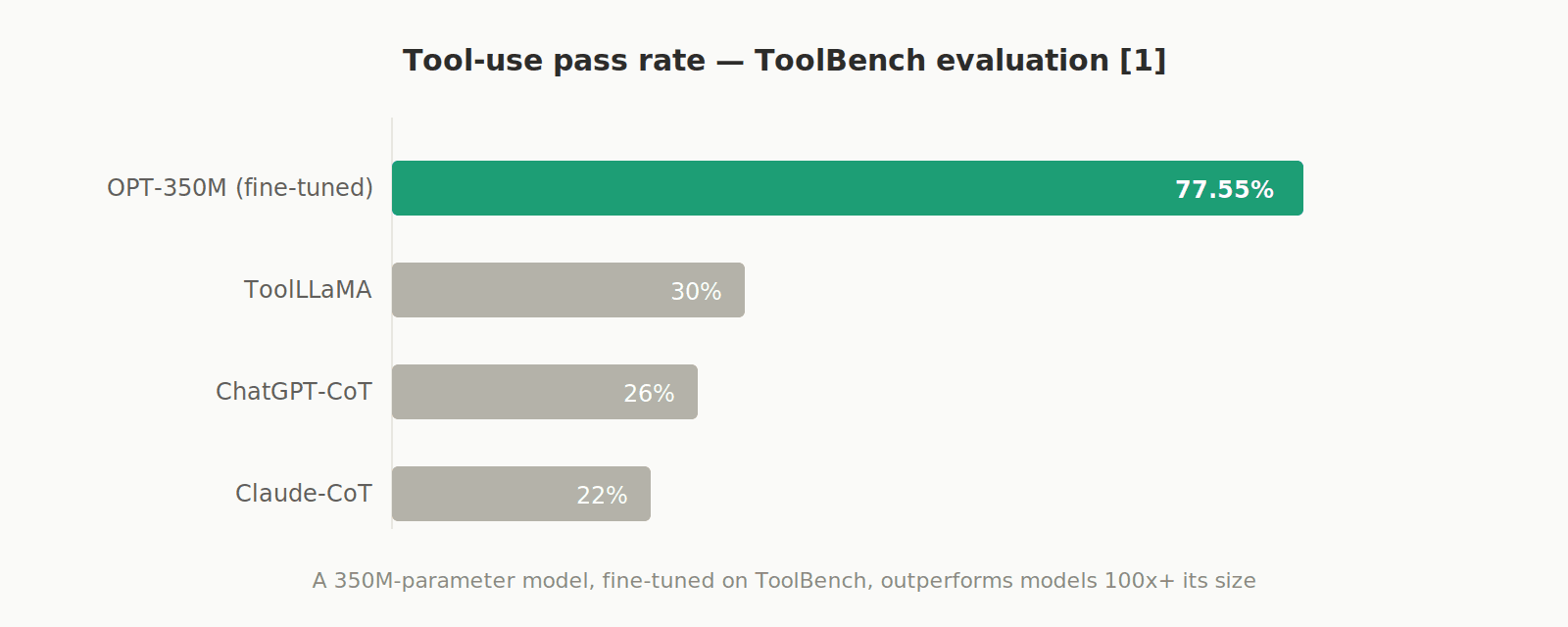
An example case is a model with only 350 million parameters (OPT-350M), fine-tuned on ToolBench data, that achieved a 77.55% pass rate on tool-use evaluations, crushing ChatGPT-CoT (26%), ToolLLaMA (30%), and Claude-CoT [1].
3. Key Architectural Innovations
There are architectures that are well known in the industry, but the interesting part is the way they are being applied to achieve better performance with SLMs.
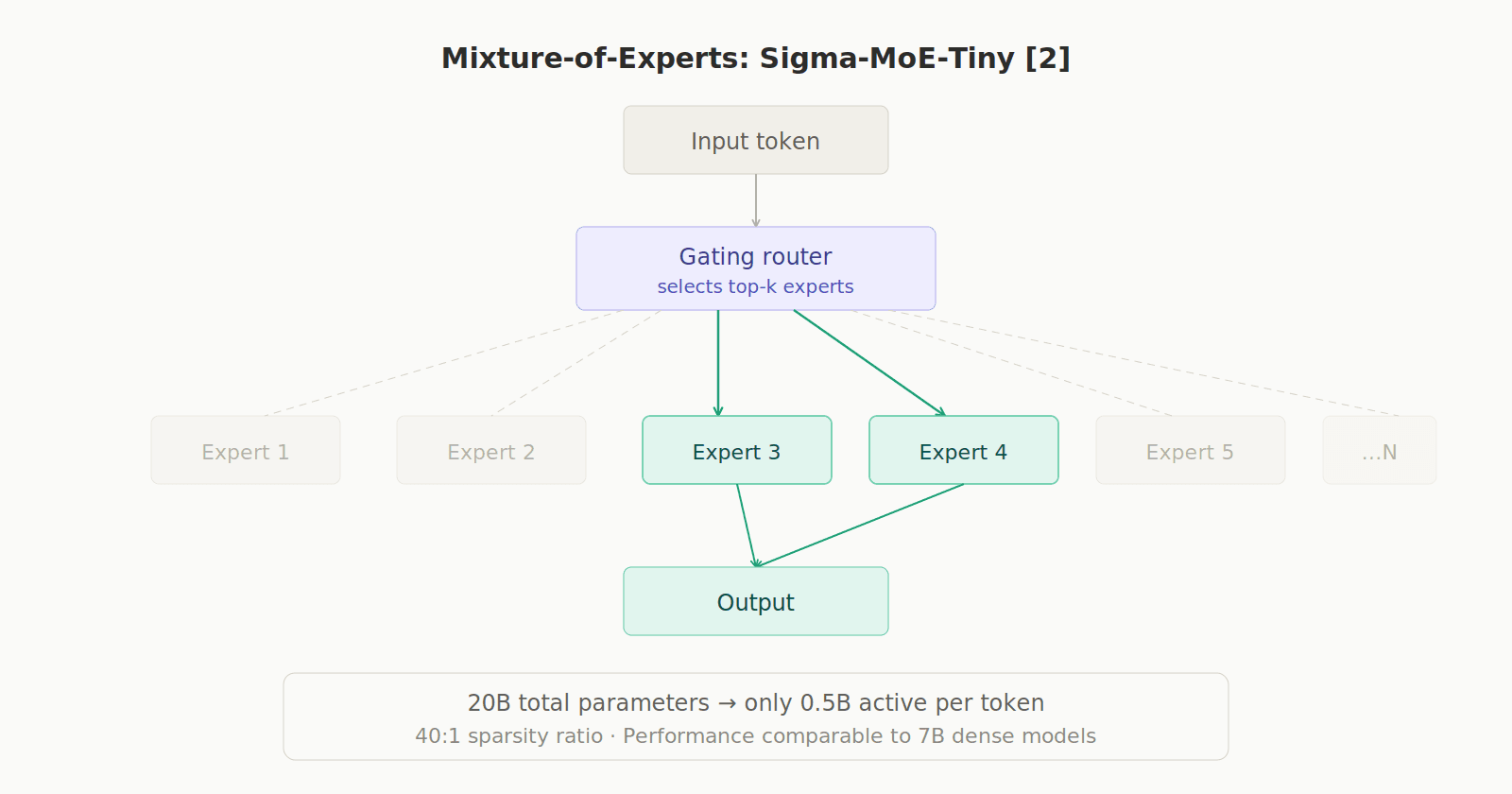
Mixture-of-Experts (MoE): Models like Sigma-MoE-Tiny have 20B total parameters but only activate 0.5B per token (a 40:1 ratio). This achieves performance comparable to 7B dense models in math and coding, with a fraction of the compute. [2]
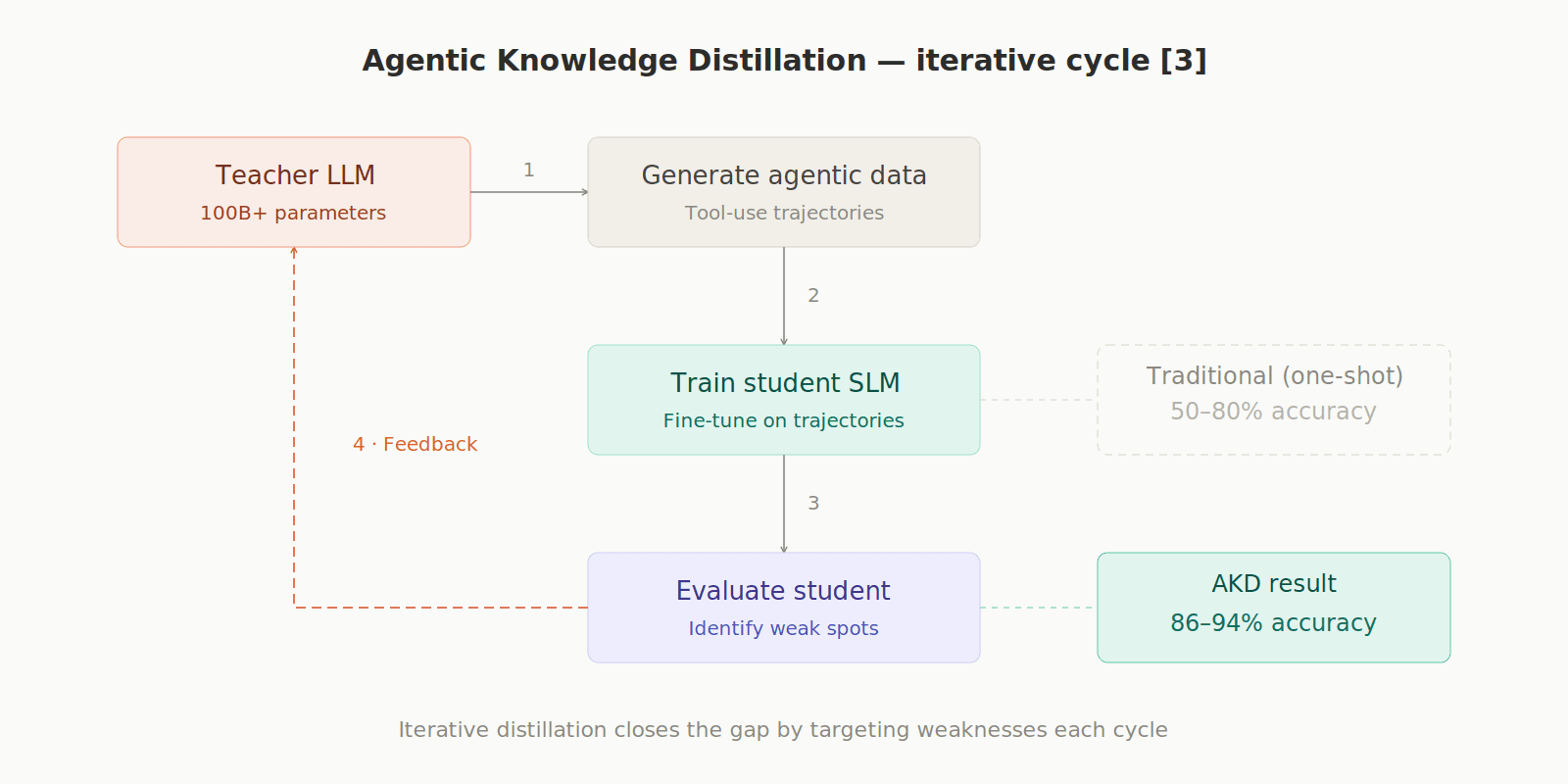
Agentic Knowledge Distillation (AKD): A large LLM acts as an "autonomous teacher" that generates data, evaluates the small model, and trains it iteratively. Models distilled this way reach 86–94% accuracy on security tasks, versus 50–80% with traditional methods. [3]
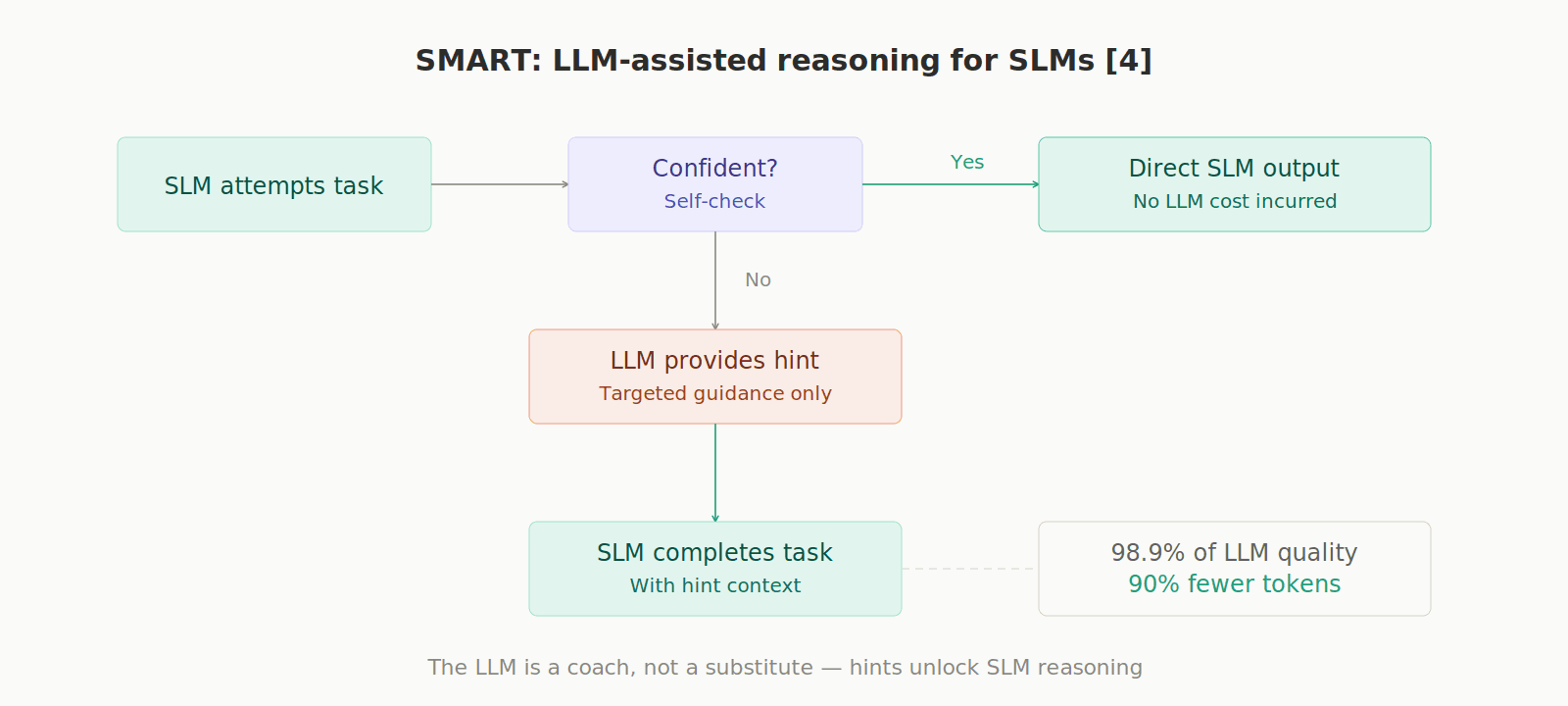
SMART Framework: When an SLM gets stuck on complex reasoning, the large LLM is invoked only to provide a targeted "hint," not to solve everything. This reaches 98.9% of the large LLM's performance while using 90% fewer tokens. [4]
4. Benchmarks
Benchmarks allow us to estimate how good models are at specific tasks, ensuring the reliability of the models.
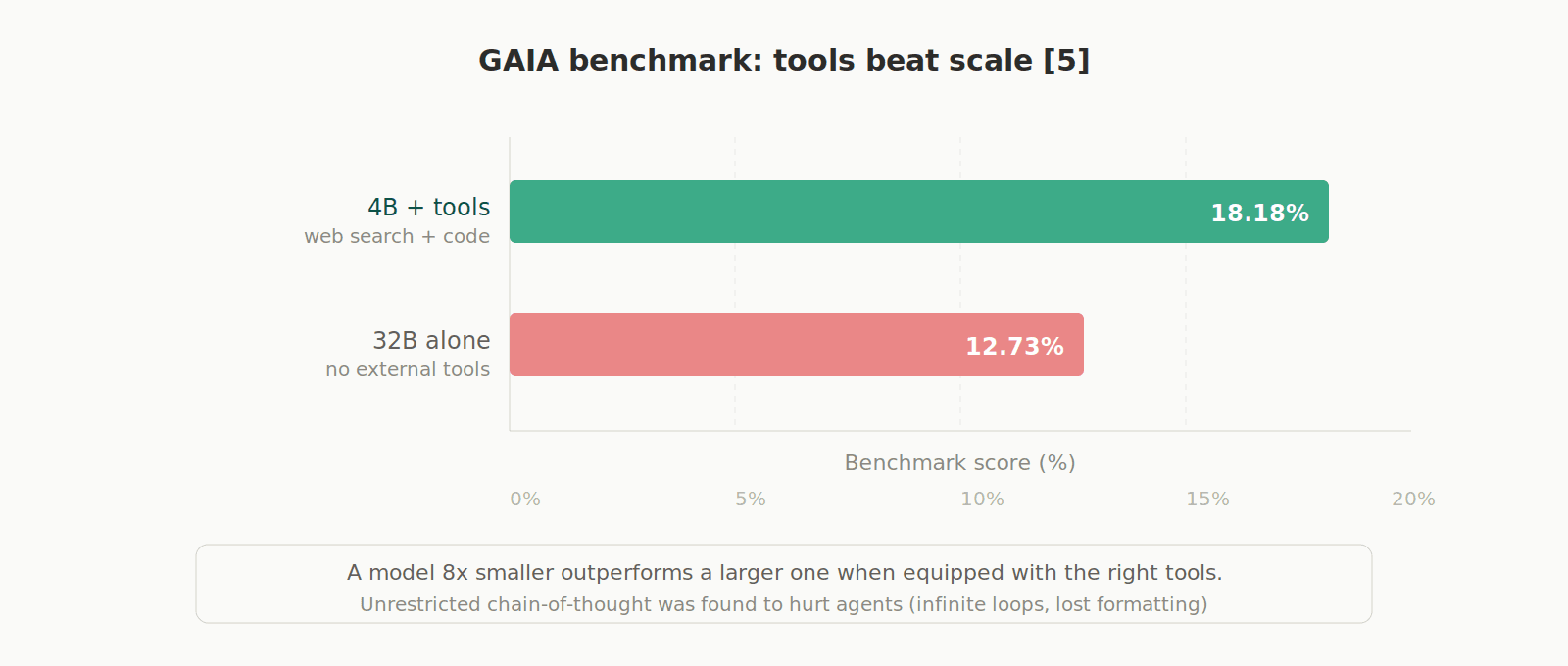
In the GAIA benchmark, 4B parameter models with tools (web search, code execution) outperformed 32B models without tools (18.18% vs 12.73%). Additionally, unrestricted "full thinking" (unconstrained chain-of-thought) was found to actually hurt agents: it causes them to enter infinite loops and lose formatting. It's better to limit reasoning to the planning phase only. [5]
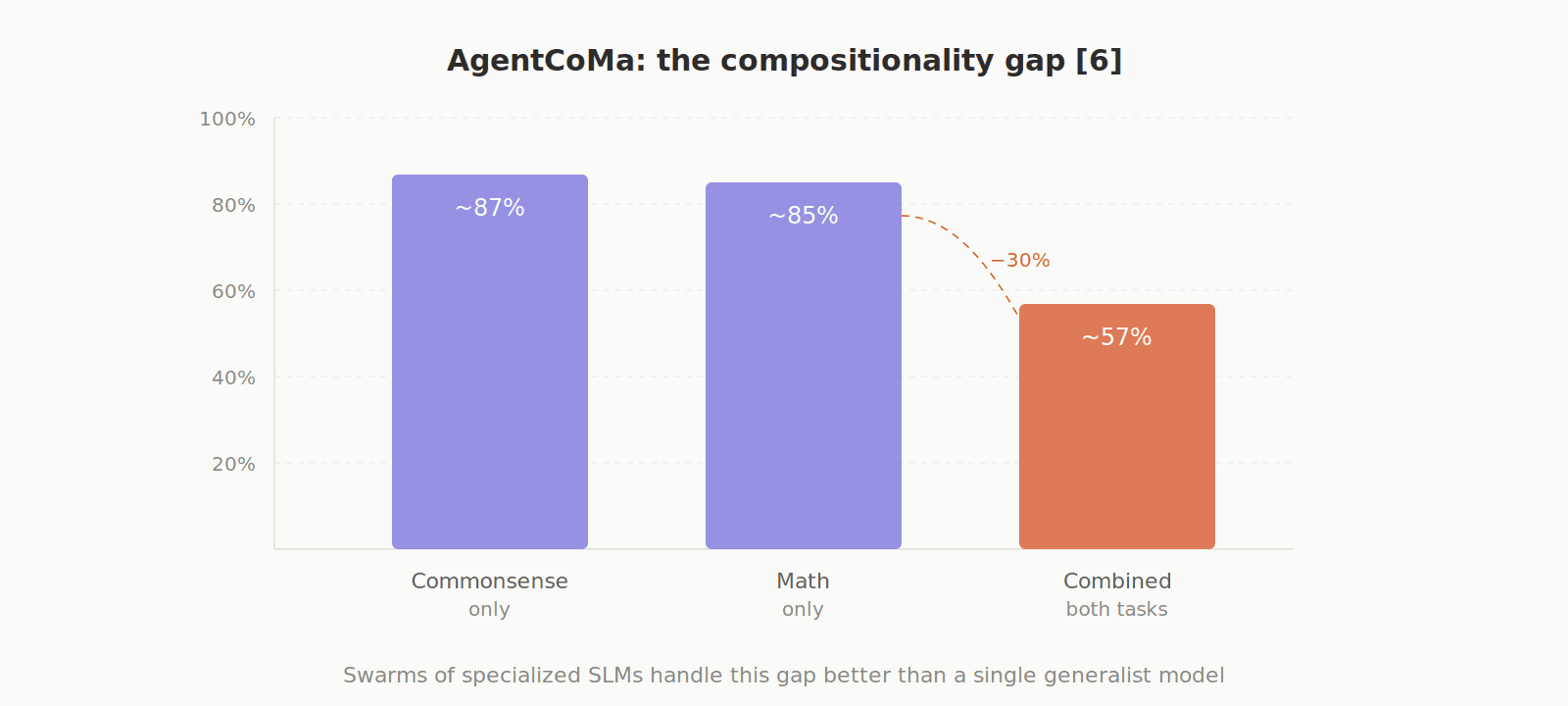
The AgentCoMa benchmark exposed another issue: the compositionality gap. Models can solve commonsense steps and math steps separately (~85%+), but when both are combined in a single task, performance drops by ~30%. This is better addressed by swarms of specialized SLMs than by a single massive generalist model. [6]
5. Multi-Agent Architectures
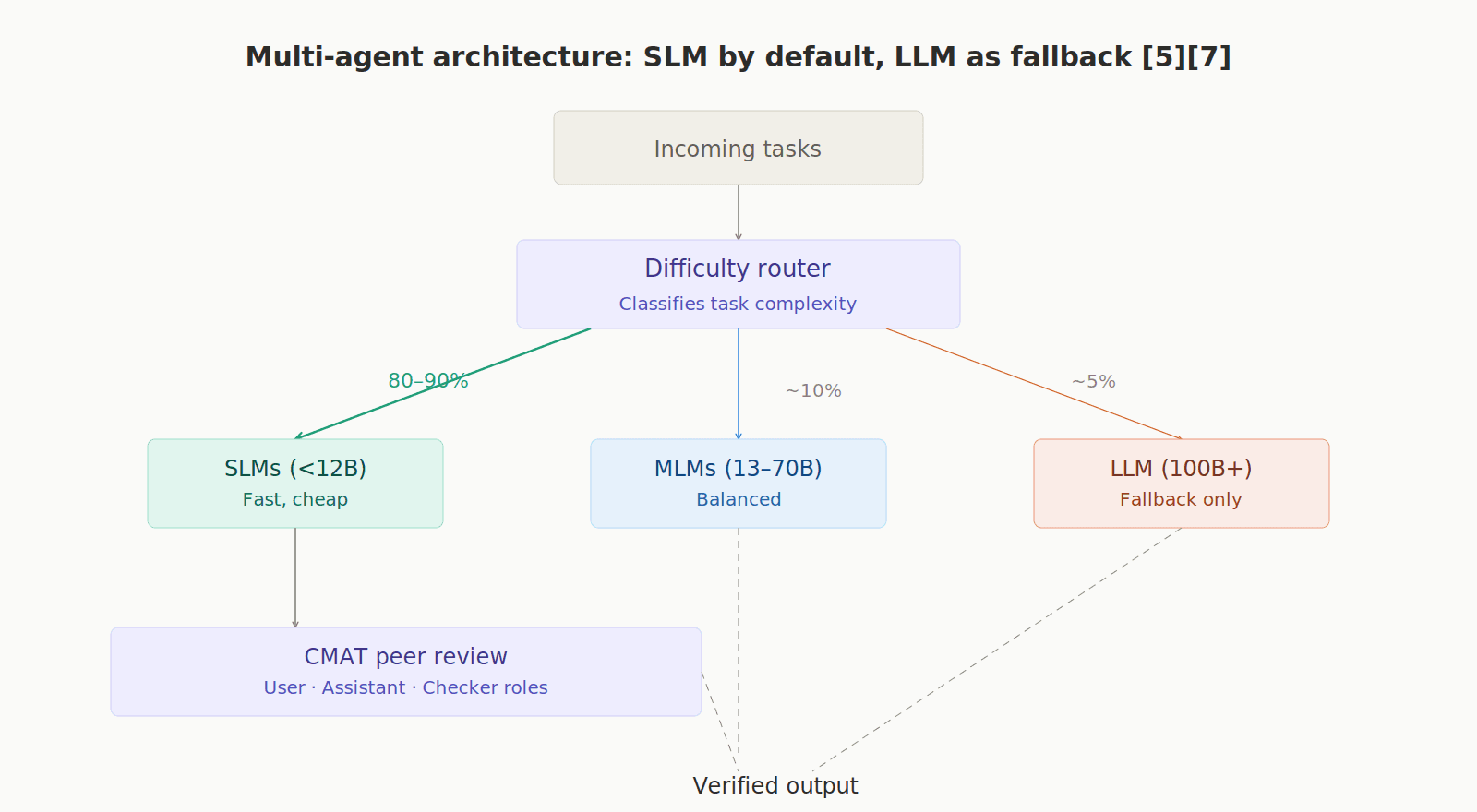
The ideal operational model is "SLM by default, LLM as fallback." A router classifies tasks by difficulty: easy ones go to cheap SLMs, intermediate ones to MLMs, and only truly complex ones escalate to the large LLM. This way, 80–90% of the workload is handled by SLMs. Frameworks like CMAT assign roles (User, Assistant, Checker) to different SLMs that peer-review each other. [7]
6. Security
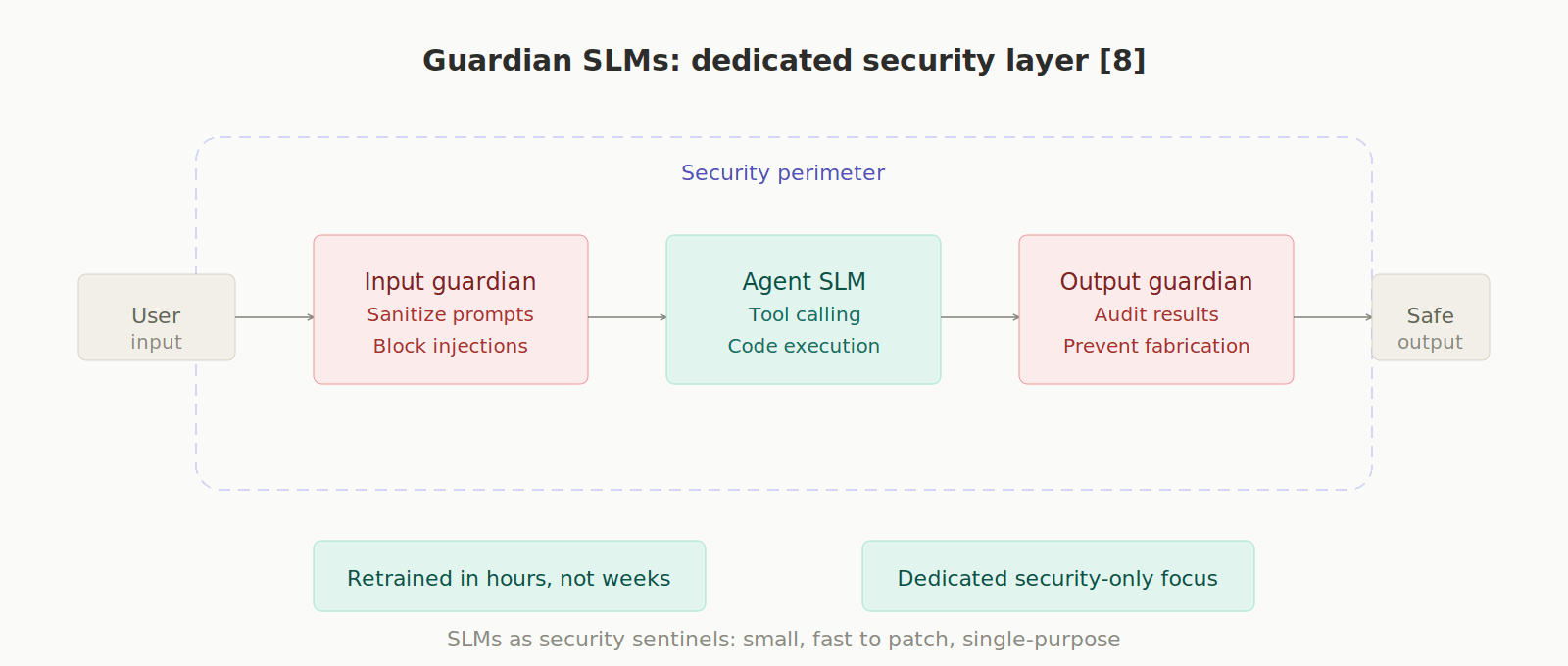
Autonomous agents with access to APIs and databases are serious attack vectors. SLMs have an advantage here: they can be patched and retrained in hours. Additionally, "Guardian SLMs" can be deployed — models dedicated exclusively to sanitizing inputs, auditing outputs, and preventing prompt injections and record fabrication. [8]
Conclusion
The future of agentic AI is being driven by four key principles that move away from the traditional massive, centralized model.
First, there's a strong focus on Economic and Latency Benefits, where smaller models (SLMs/MLMs, ranging from 1B to 70B parameters) are favored because they dramatically reduce cost, increase speed, and improve energy efficiency, making continuous, autonomous operation feasible and scalable.
This efficiency leads directly to the second principle, which emphasizes Tool Augmentation Over Pure Scale; superior performance is achieved not by building ever-larger isolated models, but by systematically integrating smaller models with programmatic tools, a synergy that consistently outperforms monolithic models.
Third, The Necessity of Specialization becomes clear: general-purpose models prove inadequate for the sheer variety of complex reasoning tasks. A "swarm" of specialized SLMs, intelligently coordinated by an efficient routing mechanism, is the most effective solution.
Finally, the role of Architecture in Efficiency is paramount, with advanced techniques like Extreme MoE, agentic distillation, and cognitive scaffolding being utilized to compress the intelligence and capabilities of frontier models into highly compact and efficient execution engines.
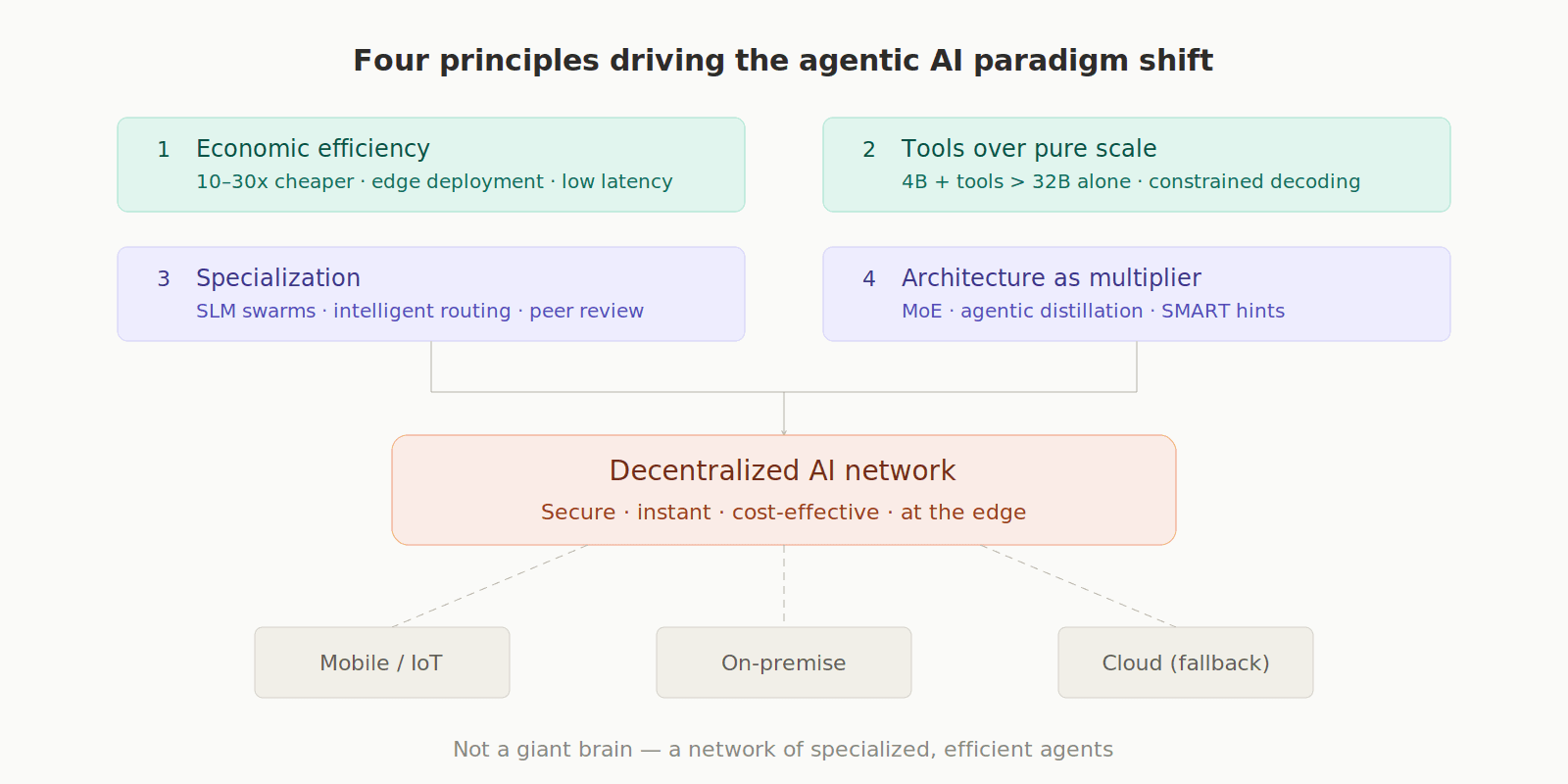
This paradigm shift means the future of agentic AI is not a centralized "giant brain," but rather a decentralized network of small and medium models operating securely, instantaneously, and cost-effectively at the periphery of the network.
References
[1] Jhandi, P., Kazi, O., Subramanian, S., & Sendas, N. (2025). Small Language Models for Efficient Agentic Tool Calling: Outperforming Large Models with Targeted Fine-tuning. arXiv:2512.15943. https://arxiv.org/abs/2512.15943
[2] Hu, Q., Lin, Z., Yang, Z., Ding, Y., Liu, X., Jiang, Y., Wang, R., Chen, T., Guo, Z., Xiong, Y., Gao, R., Qu, L., Su, J., Cheng, P., & Gong, Y. (2025). Sigma-MoE-Tiny Technical Report. arXiv:2512.16248. https://arxiv.org/abs/2512.16248
[3] Kang, M., Jeong, J., Lee, S., Cho, J., & Hwang, S. J. (2025). Distilling LLM Agent into Small Models with Retrieval and Code Tools. arXiv:2505.17612. https://arxiv.org/abs/2505.17612
[4] Kim, Y., Yi, E., Kim, M., Yun, S.-Y., & Kim, T. (2025). Guiding Reasoning in Small Language Models with LLM Assistance. arXiv:2504.09923. https://arxiv.org/abs/2504.09923
[5] Shao, C., Liu, X., Lin, Y., Xu, F., & Li, Y. (2026). Can Small Agent Collaboration Beat a Single Big LLM?. arXiv:2601.11327. https://arxiv.org/abs/2601.11327
[6] Alazraki, L., Chen, L., Brassard, A., Stacey, J., Rahmani, H. A., & Rei, M. (2025). AgentCoMa: A Compositional Benchmark Mixing Commonsense and Mathematical Reasoning in Real-World Scenarios. arXiv:2508.19988. https://arxiv.org/abs/2508.19988
[7] Shao, C., Liu, X., Lin, Y., Xu, F., & Li, Y. (2025). Route-and-Reason: Scaling Large Language Model Reasoning with Reinforced Model Router. arXiv:2506.05901. https://arxiv.org/abs/2506.05901
[8] Evertz, J., Chlosta, M., Schönherr, L., & Eisenhofer, T. (2024). Whispers in the Machine: Confidentiality in Agentic Systems. arXiv:2402.06922. https://arxiv.org/abs/2402.06922
[9] Sharma, R. & Mehta, M. (2025). Small Language Models for Agentic Systems: A Survey of Architectures, Capabilities, and Deployment Trade-offs. arXiv:2510.03847. https://arxiv.org/abs/2510.03847
[10] Belcak, P. et al. (2025). Small Language Models are the Future of Agentic AI. arXiv:2506.02153. https://arxiv.org/abs/2506.02153
Accelerate your growth with
AI-led demos.
Launch your demo in 5 minutes!
Launch your demo in 5 minutes!

Don’t make your prospects wait–ever again. Scale your demos and increase your revenue.



" height="18.00002px" id="t3TUwhEsx" transform="translate(3 3.243)" width="18px"/></svg>)
" height="16.00002px" id="eM6xJX0fQ" transform="translate(3 4.243)" width="18px"/></svg>)
" height="23.33220463282985px" id="JFXEvpVdY" transform="translate(0.489 0.333)" width="23.02237881352199px"/></svg>)
" height="23.866674065589905px" id="K2XP5s9Up" transform="translate(0 0.133)" width="23.852008219791px"/></svg>)
 scale(1 1) translate(--0.05666666666666667, -0.2982222222222222)" id="Azbtm4YKc-3318398759-radial-gradient" r="1.0639022167225811"><stop offset="0" stop-color="rgba(0, 0, 0, 0)"/><stop offset="1" stop-color="rgb(0, 0, 0)"/></radialGradient></defs><path d="M 0 0 L 24 0 L 24 24 L 0 24 Z" fill="transparent" height="24px" id="Dan82935g" width="24px"/><path d="M 11.996 24 C 12.008 22.39 11.681 20.795 11.036 19.32 C 10.44 17.896 9.573 16.6 8.483 15.507 C 7.392 14.419 6.101 13.554 4.68 12.96 C 3.205 12.315 1.61 11.987 0 12 C 1.607 12.013 3.2 11.695 4.679 11.067 C 6.098 10.453 7.388 9.577 8.483 8.485 C 9.57 7.392 10.437 6.1 11.036 4.68 C 11.681 3.205 12.008 1.61 11.996 0 C 11.996 1.663 12.304 3.223 12.929 4.68 C 13.542 6.099 14.417 7.39 15.508 8.485 C 16.606 9.577 17.899 10.452 19.321 11.065 C 20.802 11.69 22.393 12.008 24 12 C 22.39 11.988 20.796 12.315 19.321 12.96 C 17.897 13.554 16.602 14.419 15.508 15.507 C 14.417 16.605 13.542 17.898 12.929 19.32 C 12.305 20.801 11.987 22.393 11.996 24 Z" fill="url(%23Azbtm4YKc-3318398759-radial-gradient)" height="24px" id="Azbtm4YKc" width="24px"/></svg>)
© 2026 Karumi. All rights reserved.