
Toni Lopez
Co-Founder at Karumi
·
1. Introduction to Quantization
Quantization makes large language models practical to run by compressing their numerical representation, but every bit removed creates trade-offs in accuracy, robustness, and behavior.
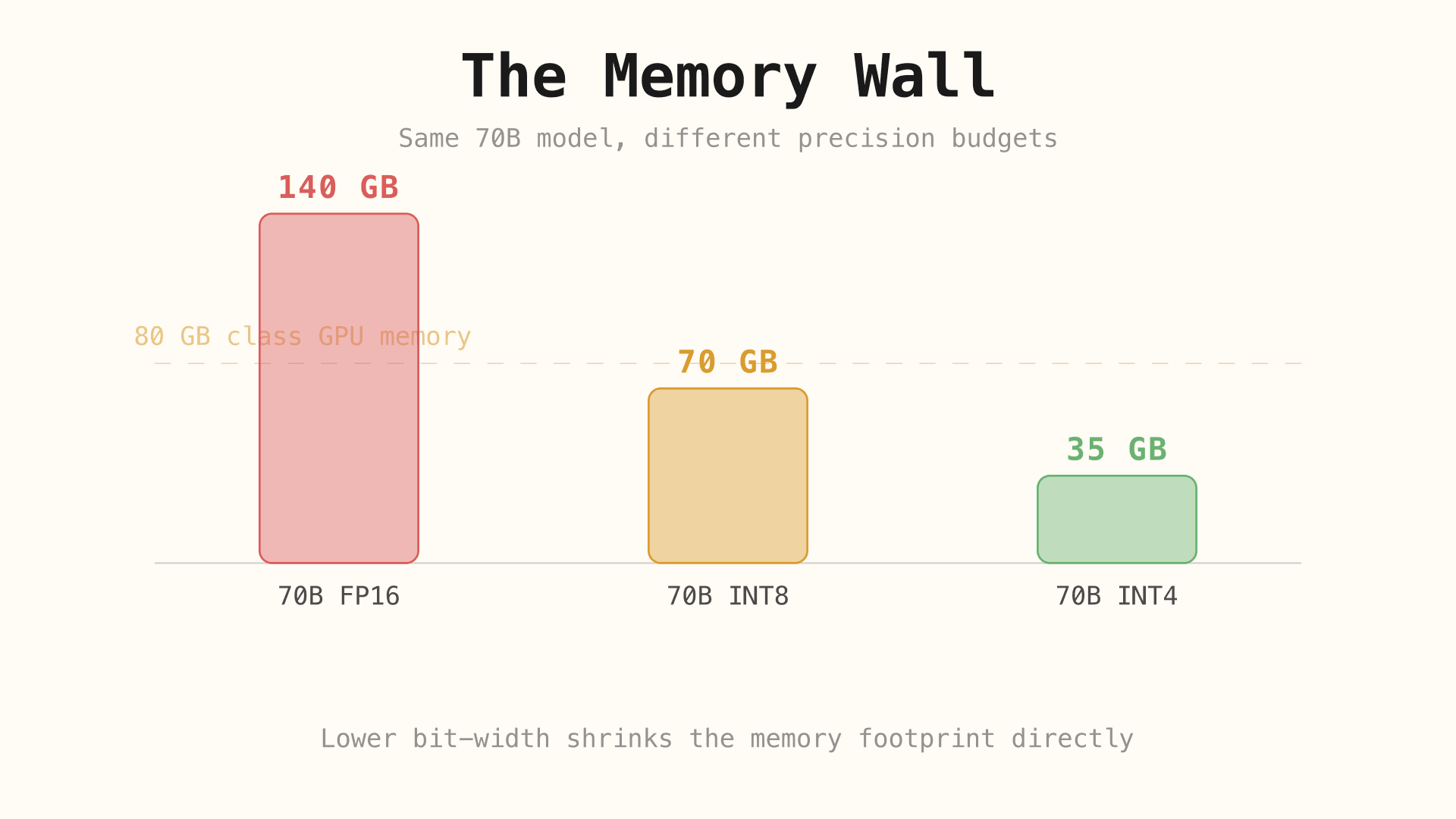
Large language models do not only scale into a compute problem; they scale into a memory problem. Every parameter must be stored somewhere, moved through memory, and read fast enough for inference to remain practical. As models grow from billions to tens or hundreds of billions of parameters, that movement of weights becomes one of the main bottlenecks.
This is what people often call the memory wall: compute hardware may keep improving, but memory capacity and bandwidth do not scale at the same pace. A model can therefore become difficult to run not because the arithmetic is impossible, but because its weights are too expensive to hold and move efficiently.
A large model in FP16 or BF16 can require far more memory than consumer hardware can provide comfortably. A 70B model stored in 16-bit precision already pushes far beyond what most local setups can load easily, and that estimate only covers the static weights. In practice, inference also needs room for activations, temporary buffers, and the KV cache [13][16].
That is why quantization is not a niche optimization. Without some form of compression, many useful models remain locked behind expensive GPUs, server-grade deployments, or aggressive offloading strategies. Quantization is the technique that turns this from a hard hardware constraint into a controllable accuracy-versus-efficiency trade-off [13][14].
This article follows that trade-off from start to finish. First, it explains what quantization is as a mathematical operation. Then it shows why the naive version of that idea breaks large transformers. After that, it maps the main modern approaches that try to control the resulting error, and finally it looks at the capabilities and behaviors that can quietly degrade when precision goes down.
2. The Basic Intuition Behind Quantization
At its core, quantization means replacing a rich numerical vocabulary with a smaller one. Instead of letting a weight take many finely separated floating-point values, we force it to live on a smaller discrete grid. The more aggressively we reduce the number of available levels, the smaller the representation becomes.
That gives us two immediate benefits. First, the model needs less memory because each weight uses fewer bits. Second, the hardware has less data to move around, which often improves practical inference speed. But those gains come from a real sacrifice: values that used to be distinct may now collapse into the same low-bit representation.
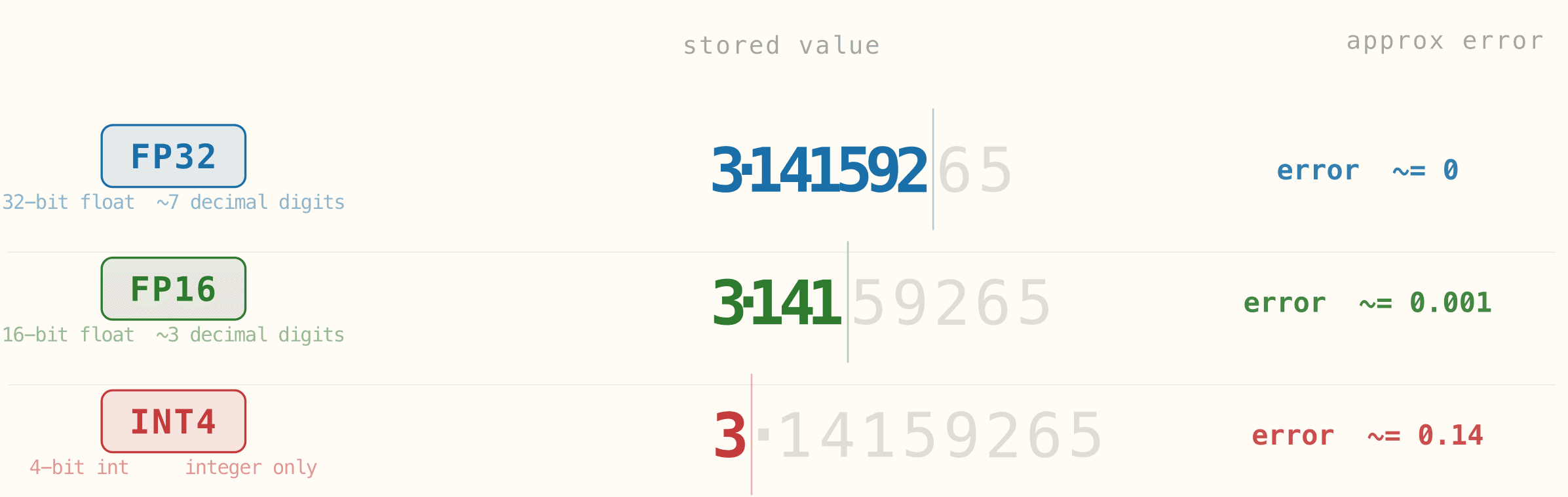
The figure below shows that sacrifice with a single value written at different precisions. In FP32, the number preserves almost all of its decimal detail, so the approximation error is effectively negligible. In FP16, part of that detail is rounded away, but the stored value is still close to the original. In INT4, the model can no longer preserve fine decimal structure at all, so the stored value becomes much rougher and the error grows sharply. The key idea is simple: the lower the precision, the less faithfully the model can store the original number.
2.1 The quantization formula
The quantization pipeline can be understood as a sequence of simple operations: scale a value, shift it into a discrete grid, round it, clip it to the allowed range, and then reconstruct it approximately during inference [1].
The blue W is the original high-precision value. The green Δ controls the size of each quantization step, which means it controls the resolution of the grid itself. The amber Z shifts that grid so zero can be represented correctly when an asymmetric mapping is needed. The red Round + Clip stage then forces the value into the discrete integer range that the target bit-width allows, producing the violet W_q.
At inference time, the model does not recover the original value exactly. It reconstructs an approximation by reversing the mapping with the same scale and offset. That is why dequantization is not a perfect inverse: once several nearby real values have been collapsed into one discrete level, the lost detail cannot be recovered.

Lower precision does not randomly damage the model. It reduces the number of distinct values the model can represent, which increases approximation error and makes nearby values harder to distinguish.
The important point is that the loss is structured. If the quantization grid is coarse, then small differences in weights disappear first. That means the model keeps the rough shape of its parameters, but loses fine-grained numerical detail. When this happens repeatedly across many tensors and layers, the accumulated error becomes the central problem every quantization method is trying to manage [3].
The next question is why that error becomes especially dangerous in large language models rather than merely mildly annoying.
3. Why Naive Quantization Fails in LLMs
The decimal example above is intentionally simple: it shows what happens when one value loses precision. Large language models fail for the same underlying reason, but at a much more difficult scale. Instead of one number being rounded, entire tensors lose resolution at once, and that loss interacts with uneven magnitudes, rare extreme values, and layer-specific sensitivities.
If model weights are just numbers, it is tempting to think that quantization is only a matter of rounding them more aggressively. In a small toy example, that intuition seems reasonable: shrink the representation, accept some error, and move on. But large transformers are not just large tables of interchangeable numbers. Their performance depends on very uneven numerical structure spread across layers, channels, and tokens.
That means naive rounding does not produce a smooth, uniform loss of quality. It can destroy precisely the distinctions the network relies on most. The result is not only lower accuracy, but sometimes a much more abrupt collapse in coherence, perplexity, or reasoning quality than a simple “less precision equals slightly more noise” mental model would predict.
3.2 Outliers, step-size inflation, and massive activations
The main failure mode is not rounding by itself but what rounding does when a tensor contains extreme values. If a tensor contains one or a few outliers with much larger magnitude than the rest, the quantization scale has to stretch to include them. That larger scale means each discrete step now covers a wider real-valued range.
Once that happens, the ordinary values in the center of the distribution lose useful resolution. Instead of being mapped to many distinct levels, they collapse into a much smaller number of buckets. In effect, the outlier forces the entire tensor to pay for its range. This is why the green Δ in the formula matters so much: when Δ becomes too large, the grid becomes too coarse for the bulk of the data.
The same idea extends beyond static weights. Large models can also develop massive activations, including token-specific spikes that behave like attention sinks. These are not harmless edge cases. They create exactly the kind of disproportionate scale problem that naive quantization handles badly [2] [5] [7].
As models grow, these pathologies become more structural. Large transformers develop outlier channels, token-level activation spikes, and behaviors that make naive quantization much less reliable. The problem is therefore not just “more parameters means more rounding error.” The problem is that larger models develop numerical geometry that is harder to compress with one crude global rule [2][3].
Once naive quantization is understood as a failure of scale management and error control, modern quantization methods stop looking like arbitrary acronyms and start looking like targeted responses.
4. How Quantization Is Actually Applied Today
4.1 Post-Training Quantization vs Quantization-Aware Training
Modern quantization usually begins with either post-training quantization or quantization-aware training. Post-training quantization adapts a model after training has finished. It is cheap, practical, and therefore dominant in open-weight inference workflows. Quantization-aware training is more expensive because it exposes the model to quantization during training or fine-tuning, but in exchange it can preserve quality better when the target precision becomes very low [1][11][12].
This first split matters because it tells us what kind of problem we are solving. PTQ asks: how much compression can we get from an existing model without retraining it? QAT asks: can the model learn to live inside a quantized regime from the start?
4.2 What modern methods try to preserve
Different methods try to preserve different things because not all quantization error is equally harmful. Some methods try to protect the weights or channels that matter most for activations. Others focus on local scaling so that one bad region of a tensor does not ruin the rest. Others are optimized around throughput, flexible bitrate targets, or making a particular hardware stack easier to exploit efficiently [6][4][5].
That is why modern quantization methods are best understood as error-control strategies. They are all trying to answer the same question: which information is too important to compress naively, and what is the cheapest way to protect it?
4.3 Main methods and deployment formats in practice
Today’s ecosystem is not a random list of acronyms, but it does mix different kinds of things. AWQ, GPTQ, and QAT are quantization methods or training approaches. GGUF and EXL2 are closer to model formats and inference ecosystems: they matter because they package or operationalize quantized models in ways that fit particular hardware and runtimes.
Name | Type | Main idea | Strength | Best fit |
|---|---|---|---|---|
GGUF | format / deployment ecosystem | portable quantized model format widely used in local inference stacks | portability and practical defaults | CPUs, Apple Silicon, heterogeneous local setups |
AWQ | quantization method | protect activation-salient weights during quantization | strong quality retention at low bit-width | GPU inference where quality matters |
GPTQ | quantization method | second-order post-training weight quantization | fast inference with good compression | throughput-oriented GPU serving |
EXL2 | format / runtime ecosystem | mixed-bitrate quantized format tuned around ExLlama-style inference | flexible memory / speed trade-off | multi-GPU or VRAM-constrained ExLlama setups |
QAT | training approach | train or fine-tune with quantization in the loop | best robustness at very low precision | cases where retraining cost is acceptable |
The point of this table is not to memorize brands. It is to notice that each row solves a slightly different layer of the problem: some rows describe how weights are quantized, while others describe how quantized models are packaged and run. The table compresses ideas drawn from the GGUF specification, AWQ, GPTQ, ExLlamaV2 / EXL2, and recent LLM-focused QAT work such as LLM-QAT and EfficientQAT [9][6][4][10][11][12].
4.4 When these methods and formats make sense
Once the trade-offs are clear, the landscape becomes easier to reason about. GGUF is the natural choice when you want broad local portability and a format that works well across CPUs and Apple Silicon [9]. AWQ and GPTQ are more natural when GPU inference is the priority, but they optimize different sides of the trade-off: AWQ tends to be favored when preserving quality matters more, while GPTQ is often chosen when throughput is central [6][4].
EXL2 makes sense when memory fitting is itself the main optimization problem and you want finer bitrate control inside a specific inference stack [10]. QAT belongs to a different category altogether: it is not a serving format, but a training-time strategy that becomes attractive when aggressive low-bit deployment matters enough to justify retraining or fine-tuning the model to survive quantization noise [11][12].
But choosing a method is only half the story. The harder question is what kinds of capability and behavior become less stable once that compression has been applied.
5. The Hidden Costs of Quantization
5.1 Capability degradation: reasoning, context, and multimodal reliability
Recent evaluations suggest that reducing precision can degrade reasoning quality and long-context behavior, and the same low-bit robustness problem can also matter for multimodal systems. These degradations are often uneven: some tasks remain stable while others deteriorate sharply. A model may preserve fluency and still lose reliability on multi-step mathematics, long-chain inference, or tasks that depend on small internal distinctions being preserved across many layers [15][16][12].
This unevenness is one reason quantization can be misleading if it is evaluated only through a small benchmark slice. A model that looks almost unchanged on short prompts may still lose quality on longer contexts, harder reasoning tasks, or multimodal inputs where the error compounds more severely [13][14][16].
5.2 Silent failures in agents and real-world behavior
Recent evaluations also suggest that quantized models can fail in quieter ways. Tool use, multi-step planning, and agentic workflows may become more brittle even when the model still appears fluent at the surface level. That is a dangerous profile because it produces models that sound competent while becoming less reliable at the exact moments where external systems, tools, or delayed consequences matter [14][17].
In practice, this means quantization should be evaluated not only as a text generation problem, but as a systems behavior problem. If a model is part of an agent loop, a retrieval stack, or a tool-calling workflow, a small loss in token-level reliability can become a much larger operational failure.
5.3 Security, bias, and alignment distortions
Recent evaluations suggest that compression can also alter safety and behavioral properties. Quantization does not automatically make a model unsafe or biased, but it can distort the mechanisms that support alignment, guardrails, and stable behavior. If some behaviors are already numerically fragile, low-bit compression can move them enough to change refusal behavior, toxicity tendencies, or robustness against adversarial prompting [13][17].
The correct stance here is neither denial nor panic. Quantization should be treated as a behavior-changing intervention whose effects need to be measured directly. It is not enough to ask whether the model is smaller and faster; we also need to ask which properties became less stable when resolution was removed.
6. Conclusion: Quantization
Quantization makes large models cheaper to store, easier to move, and more practical to deploy. It is one of the main reasons advanced models can run outside specialized infrastructure. In that sense, quantization is one of the key technologies behind the broader accessibility of modern LLMs: without it, many models would remain trapped behind hardware budgets that only a small number of users or organizations could absorb.
The same compression that makes deployment practical can also remove useful resolution from the model’s internal computation. That loss may show up as degraded reasoning, silent instability, or shifted behavior. The important lesson is that quantization is never “free.” Even when it is clearly worth doing, it changes the numerical regime in which the model thinks.
6.1 Where research is going next
Current research is pushing toward smarter low-bit methods, better protection of sensitive activations, hardware-aware formats, and finer evaluation of what compression changes beyond benchmark accuracy. The broad direction is clear: future work is not only about fitting models into fewer bits, but about learning which parts of a model can be compressed aggressively and which parts must stay numerically protected [6][12][17].
That is why quantization should be understood as a core design layer rather than a final storage trick. It sits between model quality, deployment cost, and behavioral reliability, and the best modern methods are all attempts to balance those three pressures more intelligently.
Bibliography
[1] Jacob et al. (2018). Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference. Foundational reference for scale / zero-point quantization and quantization-aware training.
[2] Dettmers et al. (2022). LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale. Core reference for transformer outliers and why naive low-bit compression fails differently at scale.
[3] Gong et al. (2024). What Makes Quantization for Large Language Models Hard? An Empirical Study from the Lens of Perturbation. Useful reference for understanding quantization error as structured perturbation rather than generic noise.
[4] Frantar et al. (2022). GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers. Primary source for second-order post-training quantization in GPT-style models.
[5] Xiao et al. (2023). SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models. Key reference for handling activation outliers in weight-and-activation quantization.
[6] Lin et al. (2023). AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration. Primary source for protecting activation-salient weights in low-bit LLM quantization.
[7] Lee et al. (2023). OWQ: Outlier-Aware Weight Quantization for Efficient Fine-Tuning and Inference of Large Language Models. Useful reference for outlier-sensitive low-bit quantization and fine-tuning.
[8] Dettmers et al. (2023). QLoRA: Efficient Finetuning of Quantized LLMs. Important reference for 4-bit quantized fine-tuning and NF4-based training workflows.
[9] ggml / llama.cpp. GGUF format specification. Official specification for the GGUF file format discussed in the deployment-oriented methods section.
[10] turboderp-org. ExLlamaV2 README and EXL2 quantization notes. Primary implementation reference for EXL2's mixed-bitrate local GPU workflow.
[11] Liu et al. (2023). LLM-QAT: Data-Free Quantization Aware Training for Large Language Models. Early LLM-specific QAT reference, especially relevant below 8-bit precision.
[12] Chen et al. (2024). EfficientQAT: Efficient Quantization-Aware Training for Large Language Models. More recent LLM-QAT work focused on practical low-bit training efficiency.
[13] Jin et al. (2024). A Comprehensive Evaluation of Quantization Strategies for Large Language Models. Broad evaluation framework covering capability, alignment, and efficiency.
[14] Lee et al. (2024). Exploring the Trade-Offs: Quantization Methods, Task Difficulty, and Model Size in Large Language Models From Edge to Giant. Large-scale comparison across models, quantizers, and benchmark families.
[15] Li et al. (2025). Quantization Meets Reasoning: Exploring LLM Low-Bit Quantization Degradation for Mathematical Reasoning. Direct evidence for reasoning degradation under aggressive low-bit quantization.
[16] Mekala et al. (2025). Does quantization affect models' performance on long-context tasks?. Primary reference for long-context degradation under quantization.
[17] Kharinaev et al. (2025). Investigating the Impact of Quantization Methods on the Safety and Reliability of Large Language Models. Reference for the safety / reliability section and why behavior changes should be measured directly.
Accelerate your growth with
AI-led demos.
Launch your demo in 5 minutes!
Launch your demo in 5 minutes!

Don’t make your prospects wait–ever again. Scale your demos and increase your revenue.



" height="18.00002px" id="t3TUwhEsx" transform="translate(3 3.243)" width="18px"/></svg>)
" height="16.00002px" id="eM6xJX0fQ" transform="translate(3 4.243)" width="18px"/></svg>)
" height="23.33220463282985px" id="JFXEvpVdY" transform="translate(0.489 0.333)" width="23.02237881352199px"/></svg>)
" height="23.866674065589905px" id="K2XP5s9Up" transform="translate(0 0.133)" width="23.852008219791px"/></svg>)
 scale(1 1) translate(--0.05666666666666667, -0.2982222222222222)" id="Azbtm4YKc-3318398759-radial-gradient" r="1.0639022167225811"><stop offset="0" stop-color="rgba(0, 0, 0, 0)"/><stop offset="1" stop-color="rgb(0, 0, 0)"/></radialGradient></defs><path d="M 0 0 L 24 0 L 24 24 L 0 24 Z" fill="transparent" height="24px" id="Dan82935g" width="24px"/><path d="M 11.996 24 C 12.008 22.39 11.681 20.795 11.036 19.32 C 10.44 17.896 9.573 16.6 8.483 15.507 C 7.392 14.419 6.101 13.554 4.68 12.96 C 3.205 12.315 1.61 11.987 0 12 C 1.607 12.013 3.2 11.695 4.679 11.067 C 6.098 10.453 7.388 9.577 8.483 8.485 C 9.57 7.392 10.437 6.1 11.036 4.68 C 11.681 3.205 12.008 1.61 11.996 0 C 11.996 1.663 12.304 3.223 12.929 4.68 C 13.542 6.099 14.417 7.39 15.508 8.485 C 16.606 9.577 17.899 10.452 19.321 11.065 C 20.802 11.69 22.393 12.008 24 12 C 22.39 11.988 20.796 12.315 19.321 12.96 C 17.897 13.554 16.602 14.419 15.508 15.507 C 14.417 16.605 13.542 17.898 12.929 19.32 C 12.305 20.801 11.987 22.393 11.996 24 Z" fill="url(%23Azbtm4YKc-3318398759-radial-gradient)" height="24px" id="Azbtm4YKc" width="24px"/></svg>)
© 2026 Karumi. All rights reserved.