
Toni Lopez
Co-Founder at Karumi
·
The architecture and methods behind Large Language Models (LLMs) went through a major transformation between 2025 and 2026. In the past, building a foundational model meant relying heavily on massive pre-training with huge amounts of raw data. This was usually followed by a basic alignment phase using Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF). However, as high-quality training data on the internet started running out, and the need for AI with genuine reasoning skills grew, the industry had to change its approach.
Both researchers and tech companies have now shifted more focus and computing power toward interactive post-training and "test-time compute" (giving models more time to process and think before answering). In this new landscape, Reinforcement Learning (RL) is no longer just a tool to adjust a model's tone or filter bad outputs. It has become one of the main engines of post-training, especially for models that need to plan, verify intermediate work, use tools, and improve their answers through longer reasoning traces.
The current state of the art, shaped by frontier models from organizations like OpenAI, Meta, Google DeepMind, Anthropic, DeepSeek, Moonshot AI, and Mistral, shows a huge variety in how policy optimization algorithms are applied. The industry has increasingly supplemented neural reward models with verifiable reward systems, asynchronous preference optimization, model-based critique, and environment feedback.
This report breaks down how reinforcement learning is applied in today's top models.
The "Classical Paradigm": RLHF Before 2025
Before the big shift in 2025, the standard way to align LLMs was heavily shaped by OpenAI's InstructGPT. This classic approach relied on Reinforcement Learning from Human Feedback (RLHF) and followed a strict three-step process. First, the model underwent Supervised Fine-Tuning (SFT) using examples written by human labelers. Second, a separate Reward Model (RM) was trained on datasets of human preferences to predict which answers humans liked best. Finally, the SFT model was optimized against this reward model using Proximal Policy Optimization (PPO), an algorithm that updates the policy while it is running.
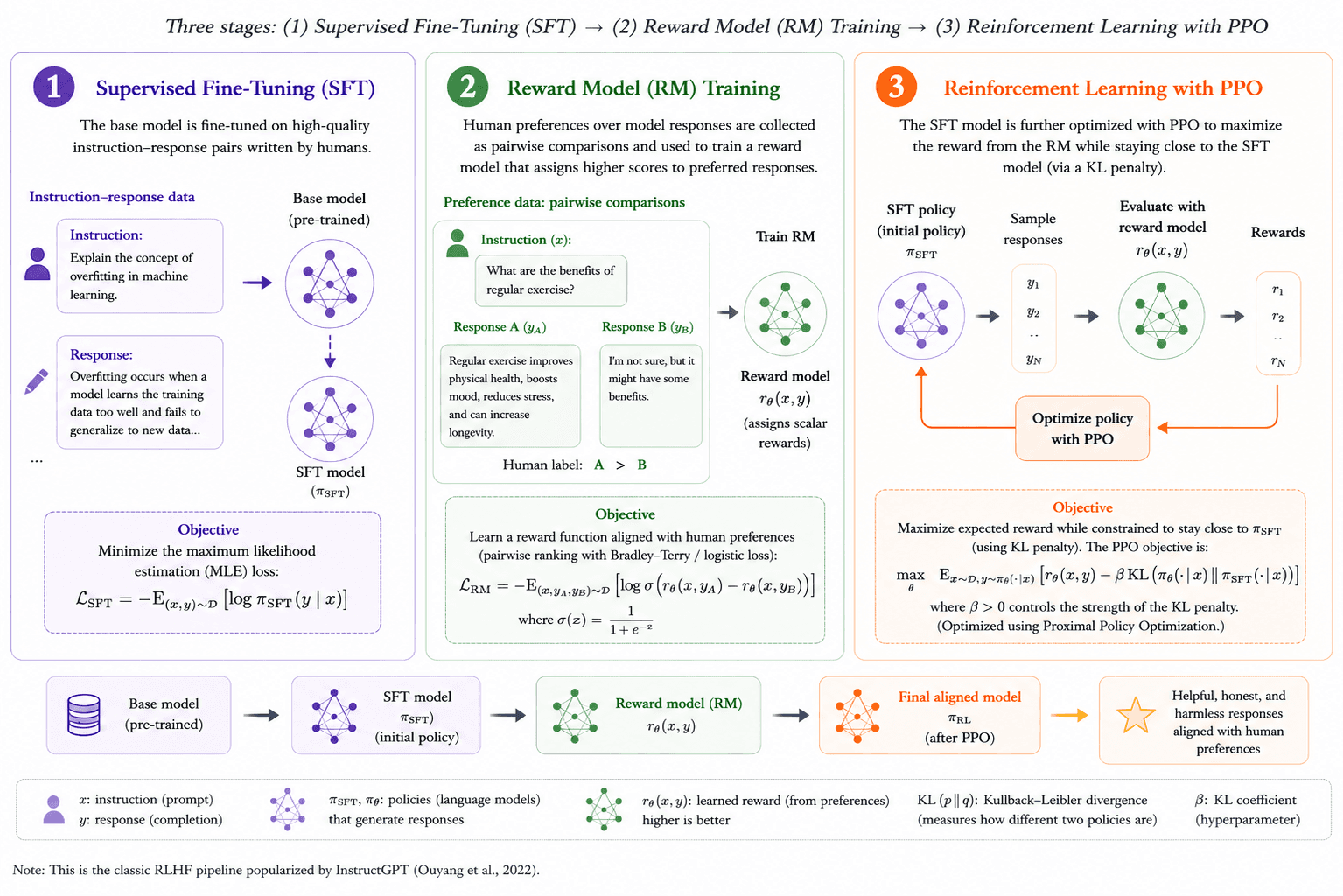
While this worked well for basic tone adjustments and following simple instructions, classic RLHF had serious flaws. It suffered from the "alignment tax", a problem where optimizing a model to sound polite or safe actively harmed its underlying reasoning and academic skills. Also, PPO was notoriously complex and required massive amounts of memory, as several models (Actor, Critic, Reference, and Reward) had to run at the same time.
In late 2023, Direct Preference Optimization (DPO) was introduced as the first major simplification. DPO proved mathematically that the separate reward modeling step could be skipped entirely, allowing the policy to be optimized directly from datasets of human preferences. However, pre-2025 DPO was strictly an "offline" method. Both PPO and DPO relied entirely on static, human-annotated data, which meant the models could never really surpass human reasoning capabilities. To break through this ceiling, the industry had to move toward verifiable rewards and the "online" methods we see today.
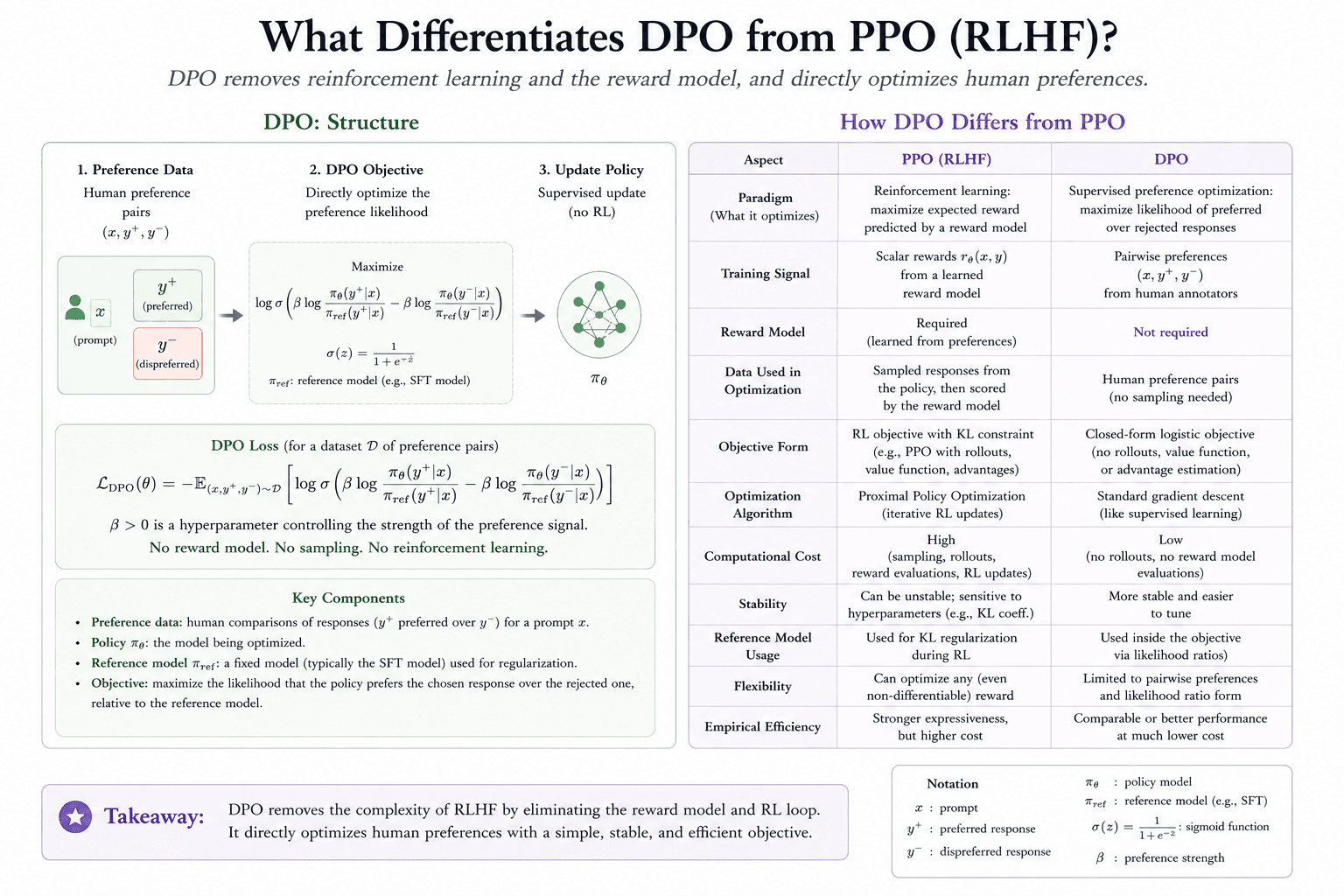
From Preference Alignment to Verifiable Rewards
The biggest change in modern LLM post-training is not simply that companies use "more RL." The deeper change is that the reward signal itself has become more diverse. Early RLHF mostly optimized for what humans preferred: clarity, helpfulness, harmlessness, and conversational tone. That was useful, but it did not give the model a reliable way to discover answers beyond what humans could easily judge.
Modern reasoning systems combine several kinds of feedback. Human preference rewards still matter for alignment and style. Direct Preference Optimization (DPO) simplifies this by learning from preference pairs without running a full PPO loop. Reinforcement Learning from AI Feedback (RLAIF) replaces some human judgments with AI-written critiques, often guided by a constitution or rubric. Reinforcement Learning from Verifiable Rewards (RLVR) goes further: it rewards answers that can be checked by rules, such as math solutions, code that passes tests, or structured outputs that match an expected format.
There is also a growing class of environment rewards. Instead of asking a human or a reward model whether an answer is good, the model acts inside an external system. A compiler can check whether generated code runs. Unit tests can verify a patch. A theorem checker, search system, browser, or tool-use environment can provide feedback that is more grounded than a preference label.
Another important split is between outcome rewards and process rewards. Outcome rewards judge only the final answer: did the proof finish, did the code pass, did the number match? Process rewards try to evaluate the intermediate reasoning steps. Verifier-reviser systems are one practical way to approximate process supervision without requiring humans to label every step by hand.
This distinction matters because training-time RL and test-time compute are related but not identical. Training-time RL changes the model's weights. Test-time compute gives the model more inference budget to sample, verify, revise, or search before answering. The strongest frontier reasoning systems usually combine both: RL teaches useful reasoning behaviors, while extra inference-time computation gives those behaviors room to unfold.
The Reasoning Revolution in Frontier Models (2025-2026)
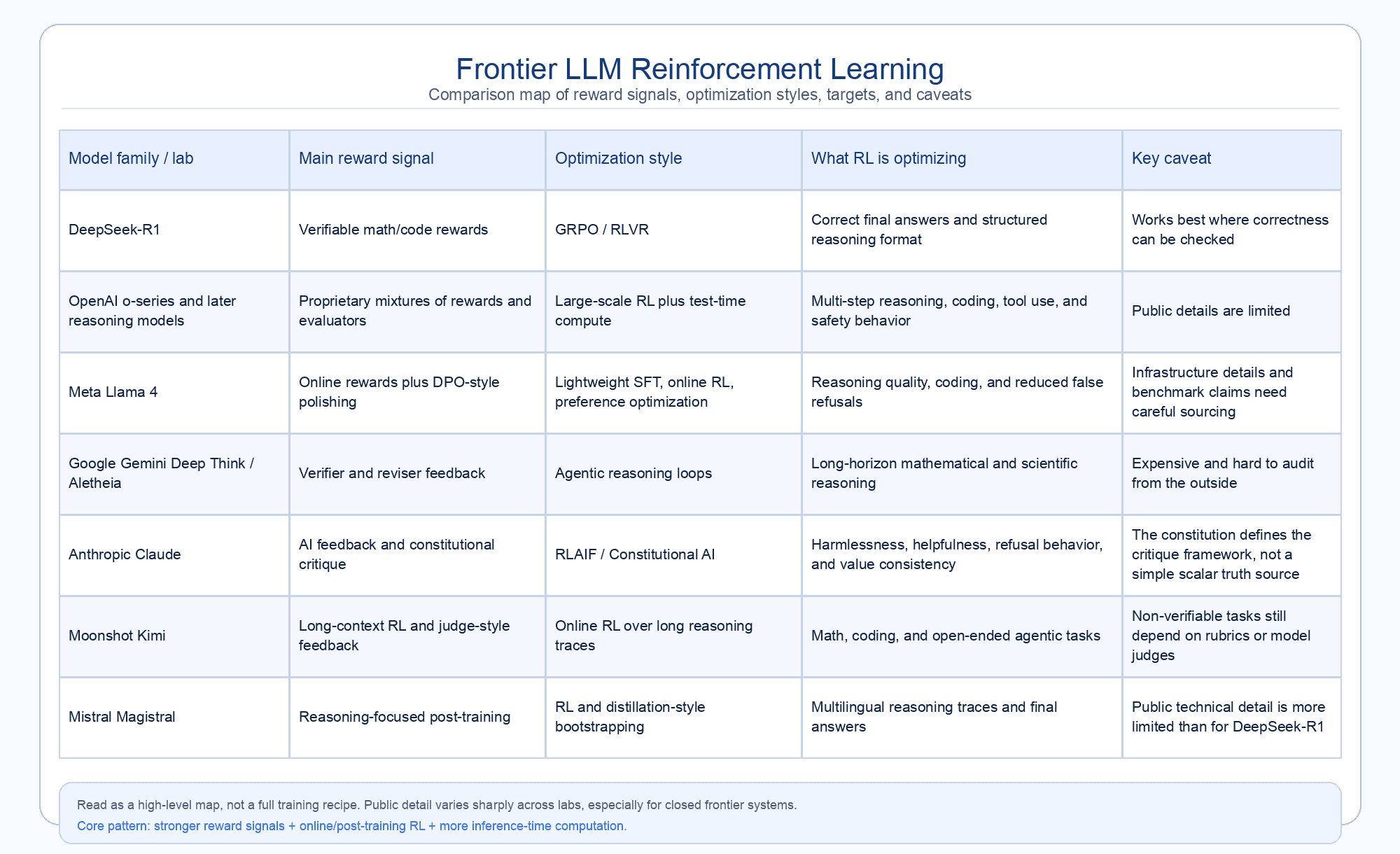
Recent research suggests that major leaps in solving complex math problems, generating code, and logical analysis do not come simply from making models bigger. They also depend on stronger post-training, better reward signals, and more inference-time computation. Different companies have tackled the same core challenge: giving rich and stable feedback to massive language models in unique ways.
DeepSeek: Verifiable Rewards and GRPO
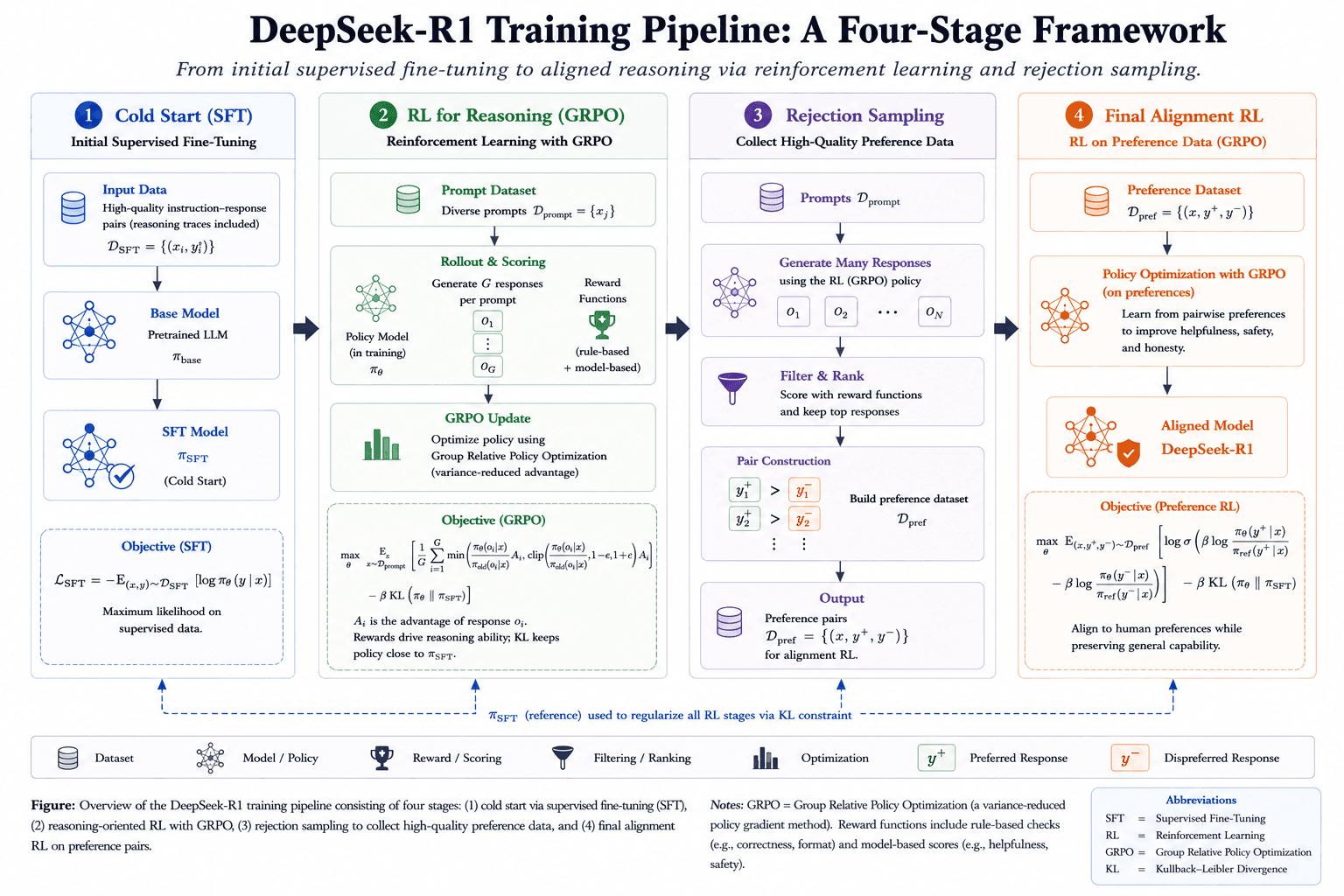
DeepSeek-R1 and its predecessor, DeepSeek-R1-Zero, made the RLVR paradigm widely visible. Challenging the traditional methods used since InstructGPT, DeepSeek researchers showed with R1-Zero that advanced reasoning skills can emerge in a base model through large-scale reinforcement learning without an initial supervised fine-tuning phase. By training a 32-billion parameter model (Qwen-32B-Base) over tens of thousands of RL steps, structured thinking behaviors emerged spontaneously, even if they were initially a bit messy and mixed different languages.
The final DeepSeek-R1 pipeline then added cold-start supervised data, rejection sampling, and additional alignment stages to make the behavior more readable, stable, and useful in practice.
To stabilize this training and scale up to the final DeepSeek-R1 model, the team used a specific algorithm called Group Relative Policy Optimization (GRPO). Unlike the old PPO standard, which required a heavy "Critic" model to calculate the baseline scores, GRPO is much lighter. It samples a group of different answers for the same prompt and scores them against each other.
This creates an objective that heavily penalizes bad answers and rewards good ones relative to their peers, while keeping updates in check to avoid catastrophic forgetting. This efficiency allowed DeepSeek to compete with massive proprietary models using only a fraction of the usual computing power.
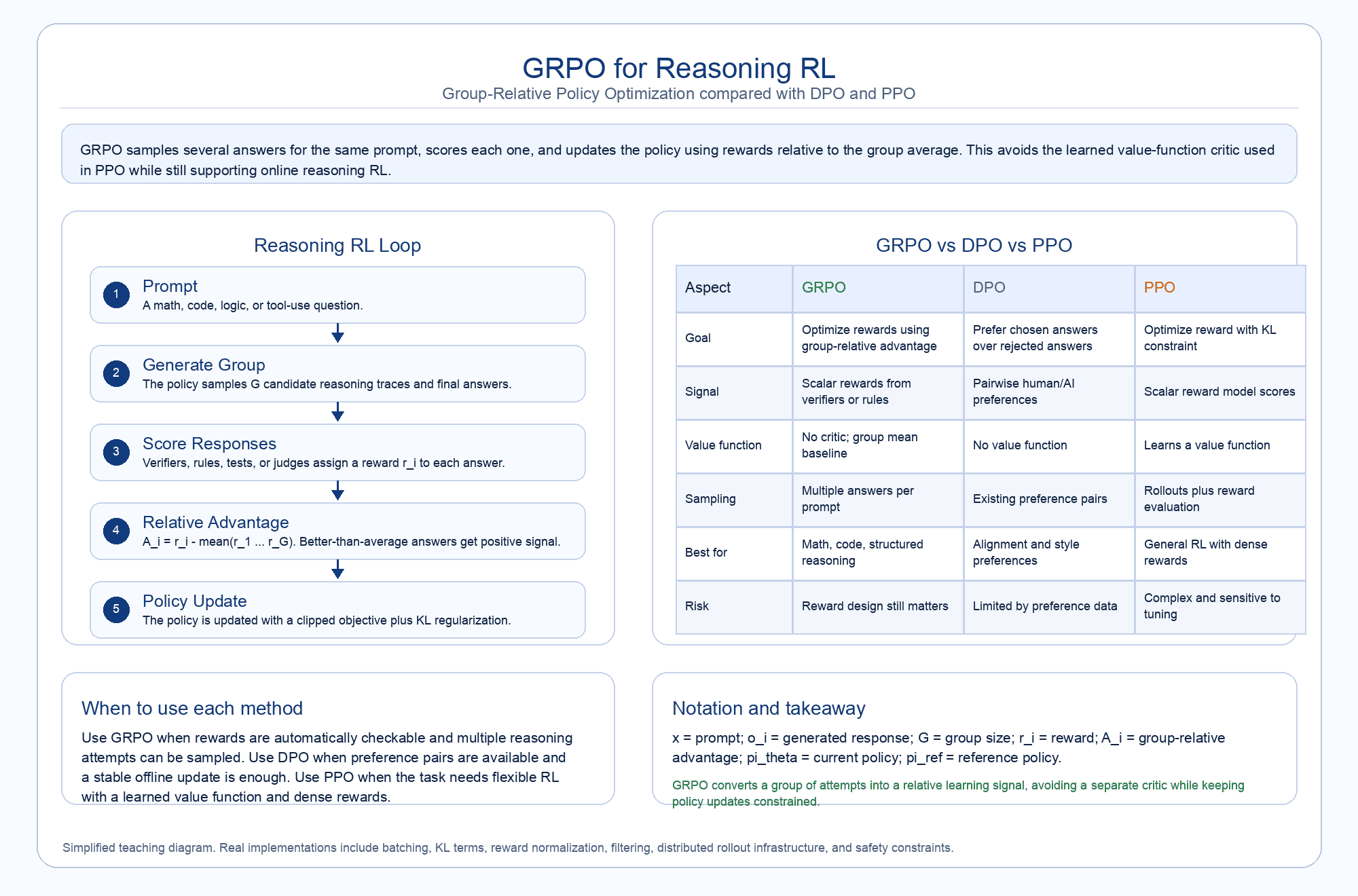
GRPO's success largely comes down to using Reinforcement Learning from Verifiable Rewards (RLVR). Instead of relying on human judges or AI reward models (which can be easily tricked or "hacked"), DeepSeek used strict, rule-based rewards. The two main rewards are for accuracy and format. The accuracy reward checks if the final answer is perfectly correct (like passing a unit test for code). The format reward forces the model to put its internal thinking process inside strict XML tags, ensuring the chain-of-thought is readable and structured.
This method later evolved into GRPO-$\lambda$. Researchers noticed that strictly penalizing a model for writing long answers (to stop it from thinking endlessly) caused sudden drops in accuracy early in training. GRPO-$\lambda$ fixes this by dynamically adjusting the penalty. If the model is getting questions wrong, it temporarily stops caring about length so the model can freely search for the solution. This smart adjustment improved accuracy on tough benchmarks like AIME 2024 and GSM8K, while surprisingly cutting the average response length in half.
OpenAI: Dynamic Reasoning, Makora and Safety
The OpenAI ecosystem, featuring the "o" series and later frontier reasoning models, has pushed reinforcement learning into domains where models need to reason for longer before answering. They use it not just for abstract thinking, but also for writing code for hardware accelerators and improving defense against cyberattacks. The core idea behind reasoning models relies on two-dimensional scaling laws: a model's accuracy can improve as more computing power is spent during RL training, and as more time is given for reasoning during testing (test-time compute).
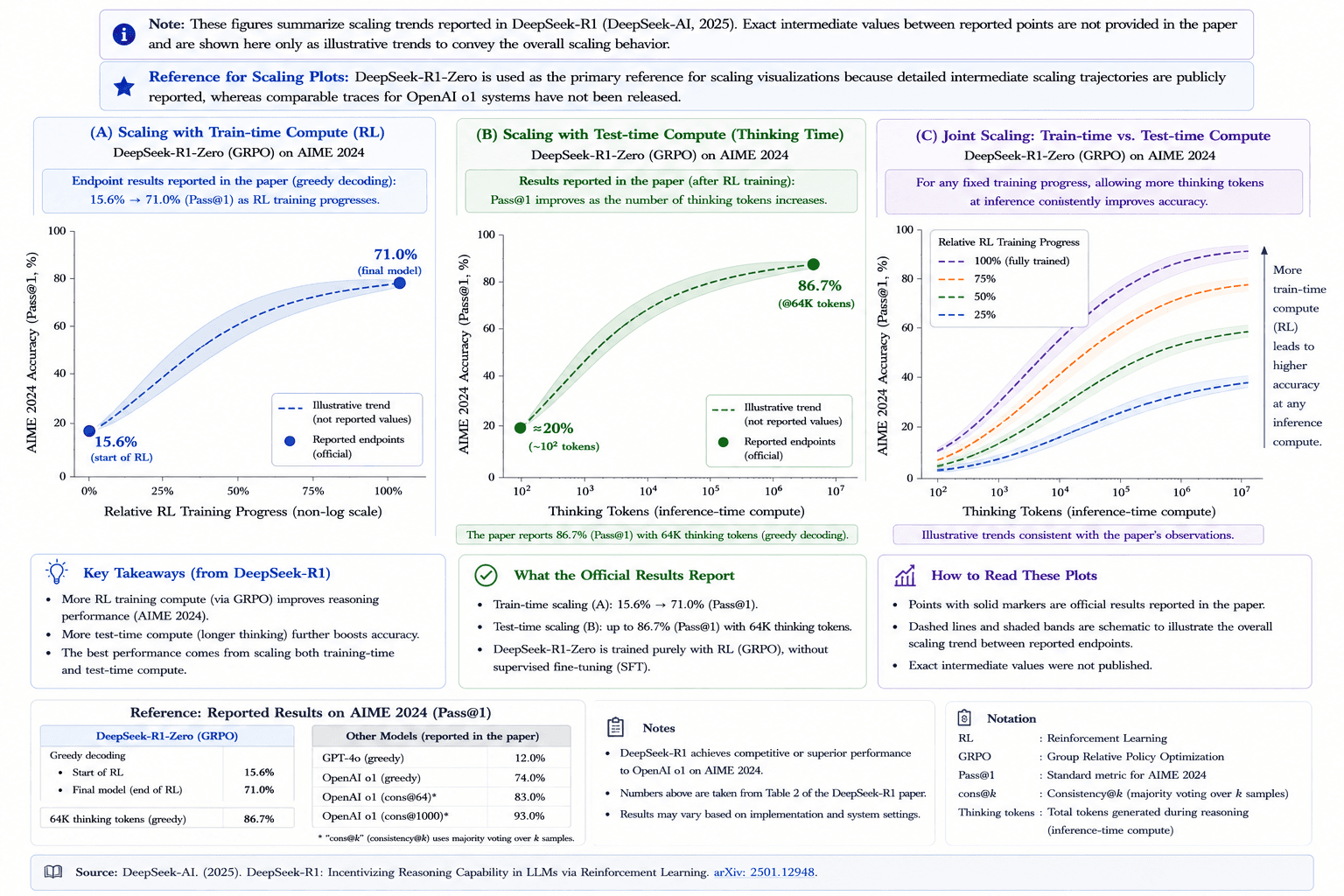
This figure uses DeepSeek-R1-Zero scaling curves as a public proxy for the general train-time/test-time scaling idea. OpenAI has described similar qualitative behavior for reasoning models, but has not released equally detailed public intermediate scaling traces.
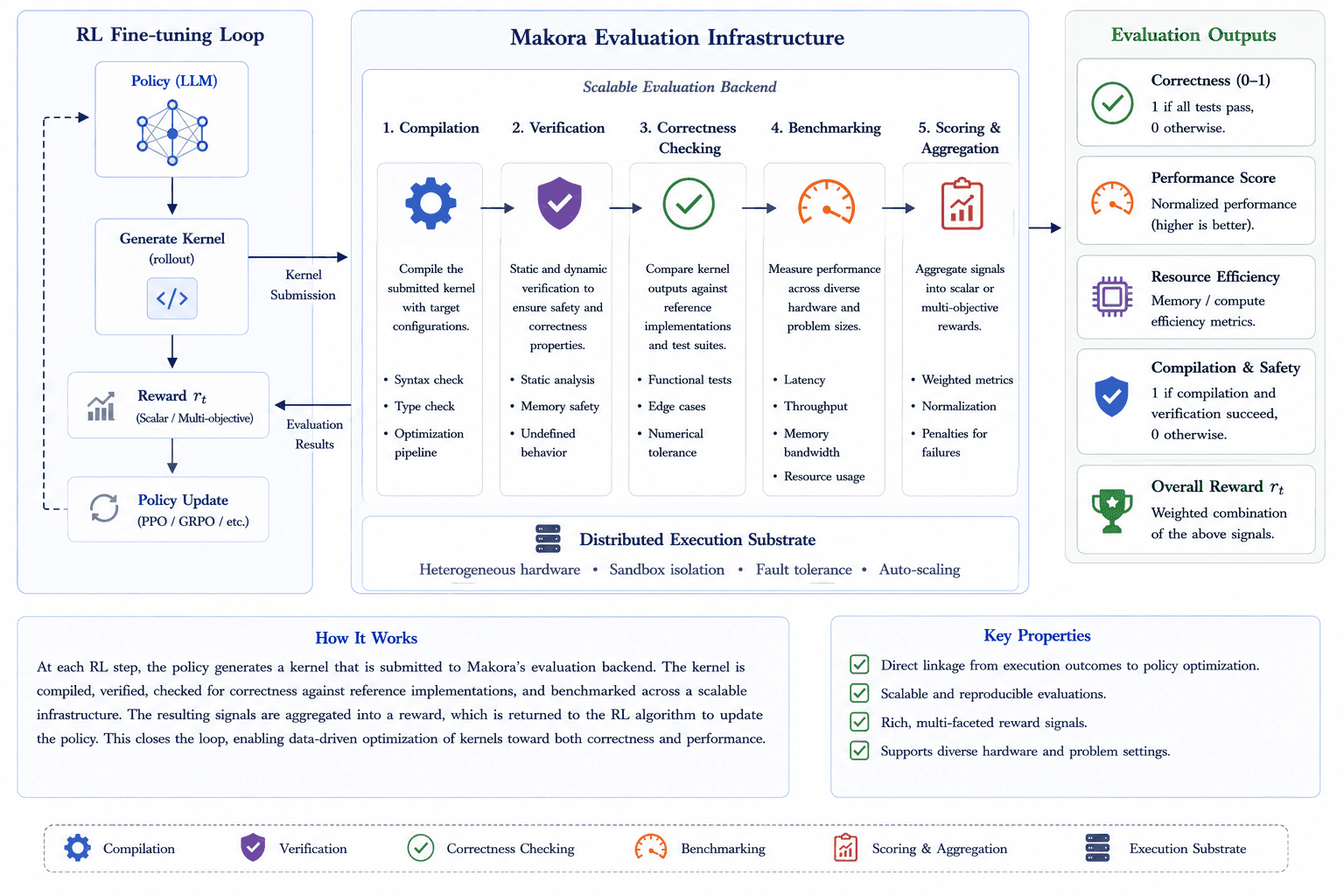
The reported results show why this paradigm became so influential. On math and science benchmarks, deep RL and extra inference-time computation appear to push reasoning models far beyond ordinary chat models. But perhaps the most interesting application is using RL in highly technical fields where there is little or no human training data available. Through an evaluation system called Makora, OpenAI treated the writing of code kernels (highly optimized code for hardware) as a pure RL problem.
The LLM writes a proposed piece of code, which is sent to a backend system that compiles it, checks if it works, and measures how fast it runs. The faster it runs, the higher the reward. This closed the loop directly between real-world software performance and the model's learning. This technique allowed the model to write code that was twice as fast as standard compilers in the majority of tests.
Meta Llama 4: Asynchronous Optimization and Lightweight DPO
Meta's approach with its Llama 4 family (which includes Scout 17B, Maverick 17B, and the Behemoth 288B model) shows a different way to scale online reinforcement learning for open-source models. Unlike older models that relied on massive amounts of supervised data, Llama 4's reported post-training uses a lean and targeted pipeline: a bit of lightweight SFT, followed by heavy online RL, and finished with a Direct Preference Optimization (DPO) polish.
The big technical idea in Llama 4 Maverick's post-training is its asynchronous RL infrastructure. Normally, algorithms like PPO or GRPO generate text and update the model on the same server node. This creates a bottleneck because the training GPUs can sit idle while waiting for rewards to be calculated. Meta describes splitting the workload so reward computation runs independently, masking the time it takes to evaluate complex rewards such as code tests.
During this phase, Meta emphasizes difficult prompts. Afterward, the final DPO layer helps polish tone and reduce cases where the model falsely refuses to answer a safe question. This makes Llama 4 a useful example of a hybrid post-training stack: RL for harder reasoning behavior, then preference optimization for user-facing behavior.
Google Gemini Deep Think: Autonomous Research and Aletheia
Google DeepMind's ecosystem, specifically Gemini Deep Think and related research agents, represents one of the clearest examples of reinforcement learning applied to long-horizon scientific reasoning. While many models optimize single answers, Deep Think-style systems frame reasoning around autonomous, multi-part agents. The most advanced example is the mathematical agent, Aletheia.
Aletheia doesn't rely on strict programming languages to prove math; it operates entirely in natural English. It uses a reinforcement loop with three parts: a Generator, a Verifier, and a Reviser. When given a hard theorem, the model writes out possible solutions. If the Verifier spots a small mistake, it doesn't just throw the whole answer away. Instead, it passes it to the Reviser to fix the logic. The answer is only scrapped if there is a massive, unfixable error. Aletheia can also use external search and scientific literature retrieval to validate claims and avoid making up fake citations.
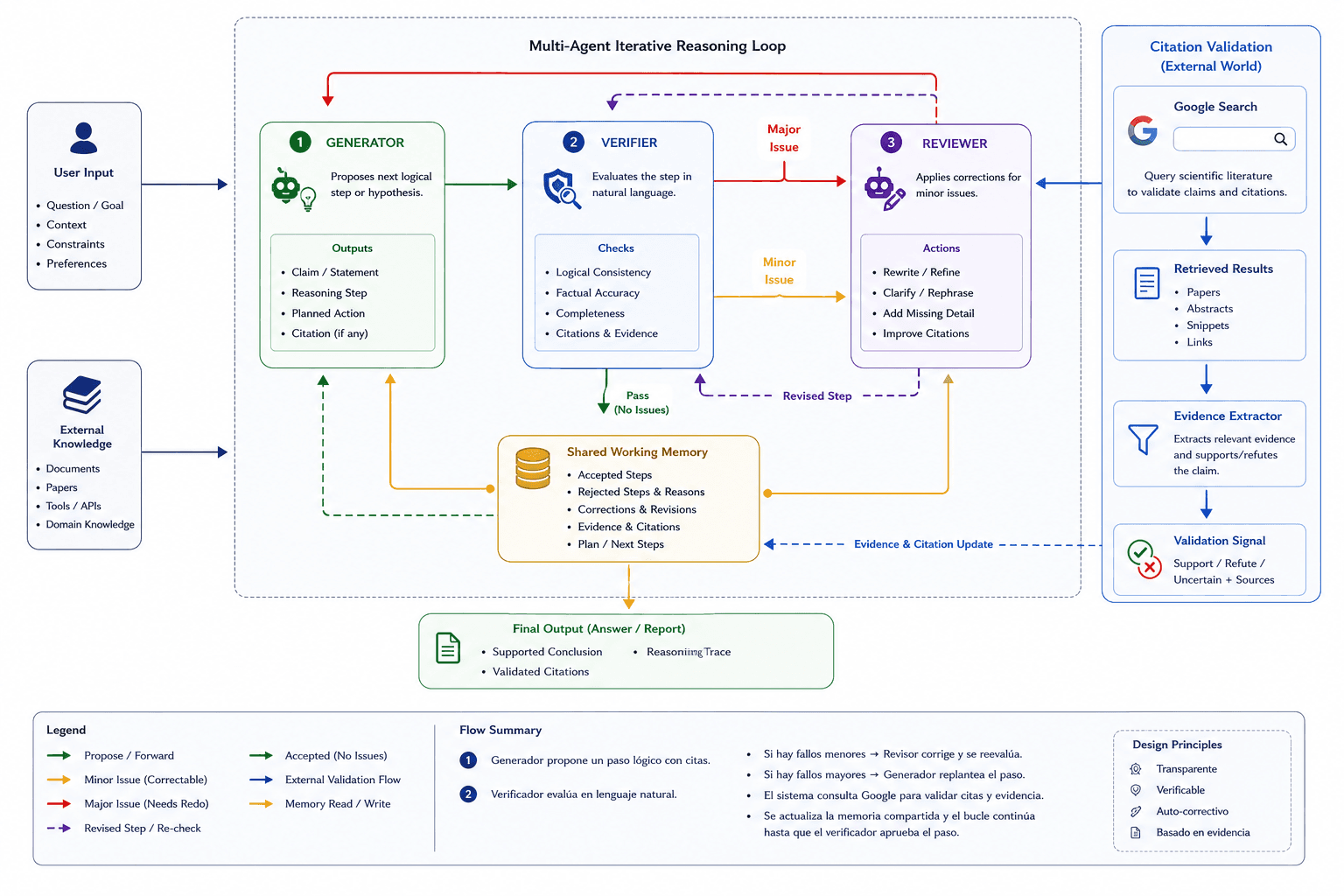
Aletheia's reported results suggest that verifier-reviser loops can push natural-language mathematical proof systems well beyond ordinary single-pass generation, especially on difficult proof benchmarks. Even more impressively, Aletheia has been described as capable of producing substantial mathematical research artifacts and inspecting machine learning algorithms. The important technical point is not just the score, but the loop: generate, verify, revise, and only then accept the proof.
Anthropic Claude: Formal Constitutions and RLAIF
Anthropic's approach with Claude 3.5 and Claude 4 focuses on Constitutional Artificial Intelligence. Instead of relying on thousands of human workers to judge which response is better, a process that is slow, biased, and difficult when dealing with toxic content. Anthropic uses an AI model guided by a written set of rules (a "constitution").
This method, called Reinforcement Learning from AI Feedback (RLAIF), forces the model to generate an answer, critique itself based on explicit rules (like human rights and utility principles), and rewrite its output to comply. These polished answers are then used to update the model. Evidence shows that this rule-based technique matches or beats classic human-feedback methods. More importantly, it ensures the model's core values are transparent, easy to audit, and quick to update without spending months gathering human data.
In late January 2026, Anthropic published a major update to this framework, releasing "Claude's New Constitution." Shifting from a simple rule-based approach to a more reason-based alignment document, it establishes a priority hierarchy around safety, ethics, compliance, and helpfulness. The constitution does not magically solve alignment by itself. Its role is to define the critique framework used to generate, filter, and rank responses during training and evaluation. By making the document public, Anthropic also made its alignment philosophy easier to inspect and debate.
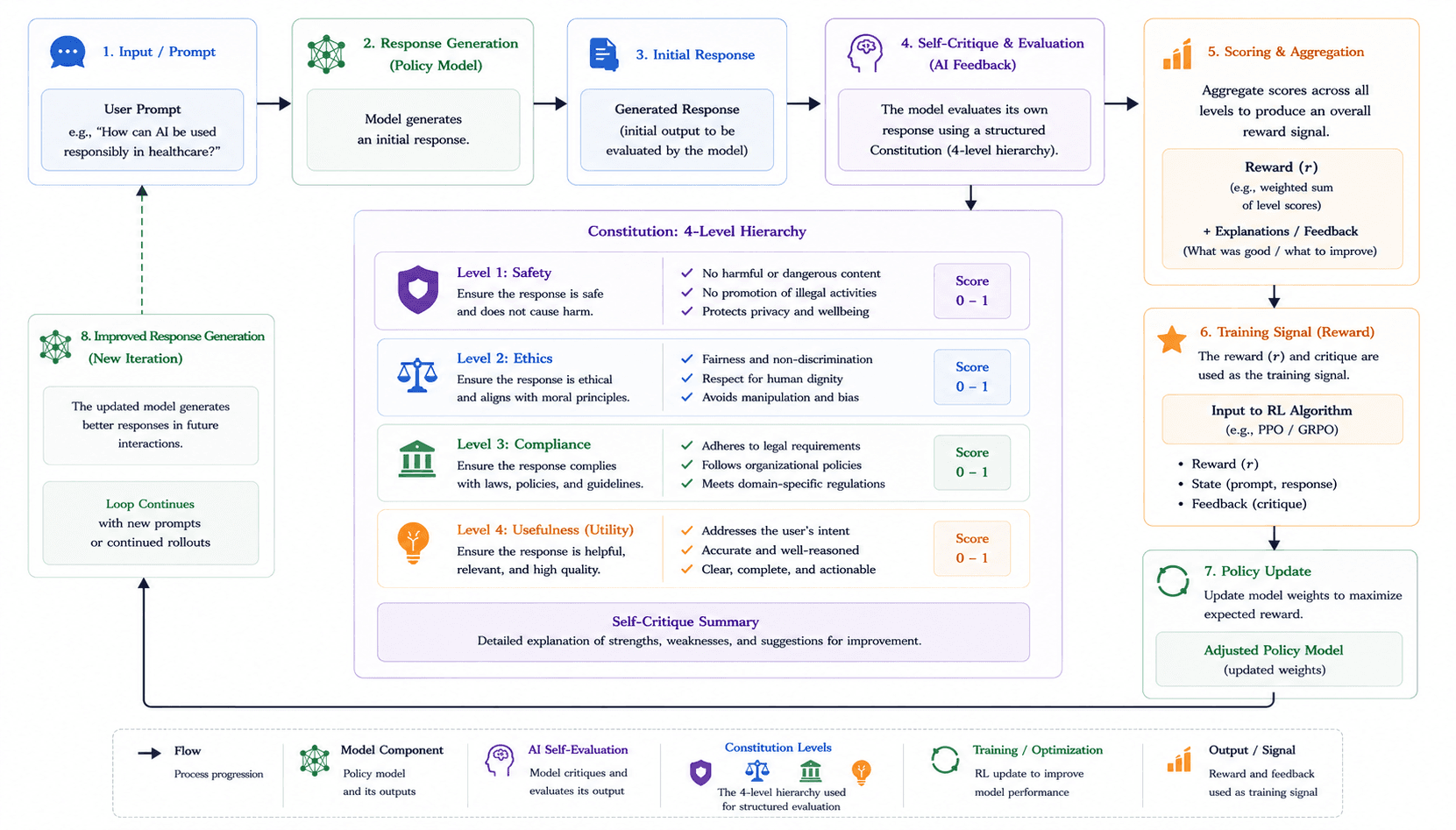
Moonshot AI Kimi: Scaling RL to Non-Verifiable Tasks
Moonshot AI launched Kimi k1.5 and K2, pushing the boundaries of what RL can achieve outside of strict mathematics and coding. The main challenge with RL has historically been evaluating non-verifiable tasks, such as creative writing, search aggregation, or complex report generation, where an absolute "right" or "wrong" answer doesn't exist. Moonshot solved this by systematically deploying Generative Reward Models (GRMs) across a broad range of agentic behaviors. Instead of simple scalar scores, Kimi leverages an LLM-based "log judge" (e.g., Kimi-K2-Thinking) that uses a self-critique rubric to evaluate open-ended generation, deciding, for instance, whether an execution log proves that a software patch successfully removed a failure pattern.
Furthermore, Moonshot AI discovered that scaling the context window to 128k tokens during the RL phase naturally allows the model to run implicit searches over the reasoning space via auto-regressive predictions. This established a simple but effective RL framework. Because the model can utilize massive context to plan, reflect, and correct itself, Kimi achieves strong results on math, coding, and vision-language reasoning tasks without needing computationally heavy architectural tricks like Monte Carlo Tree Search (MCTS) or traditional Process Reward Models (PRMs).
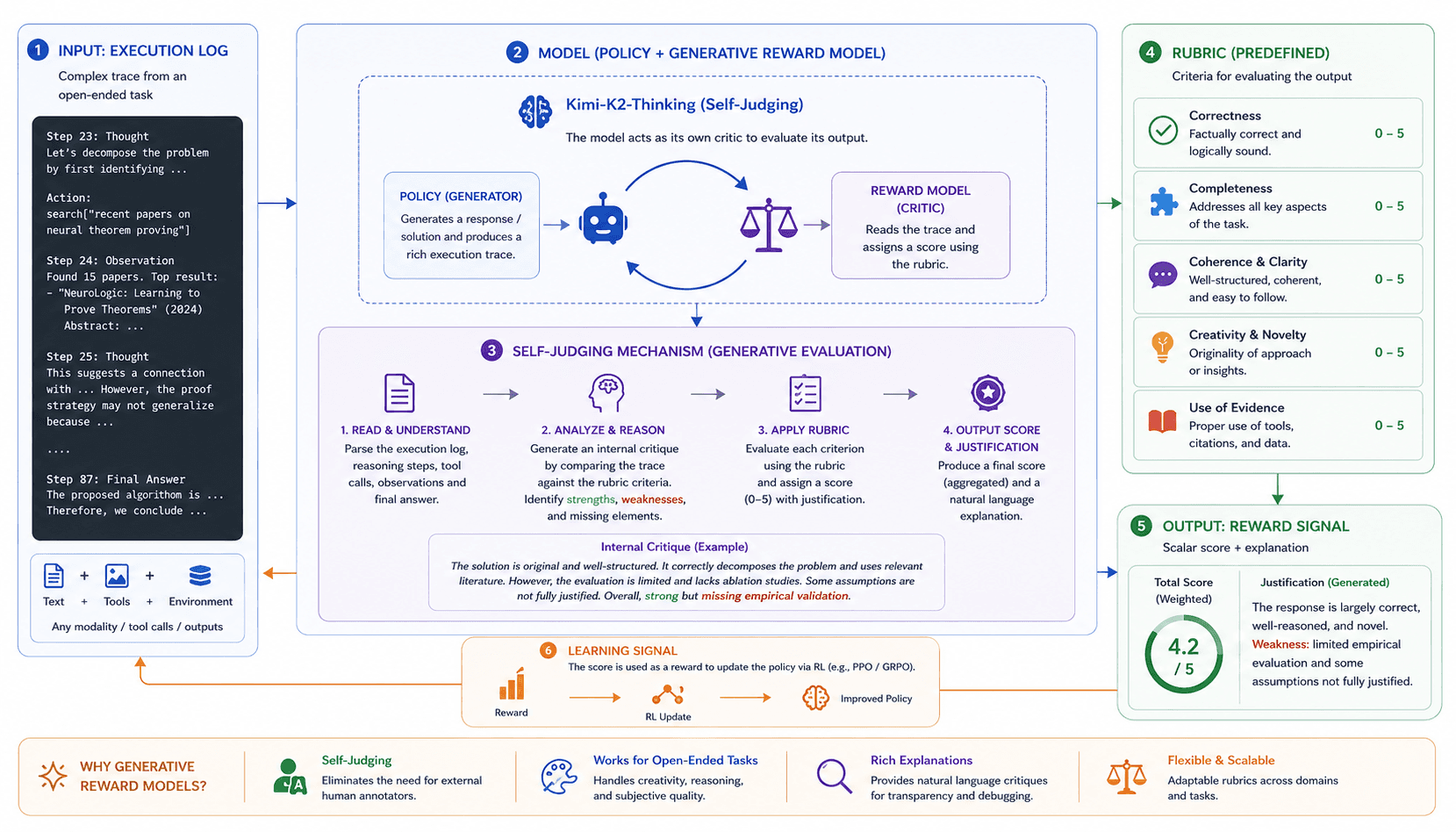
Mistral AI: Magistral and Multilingual Reasoning
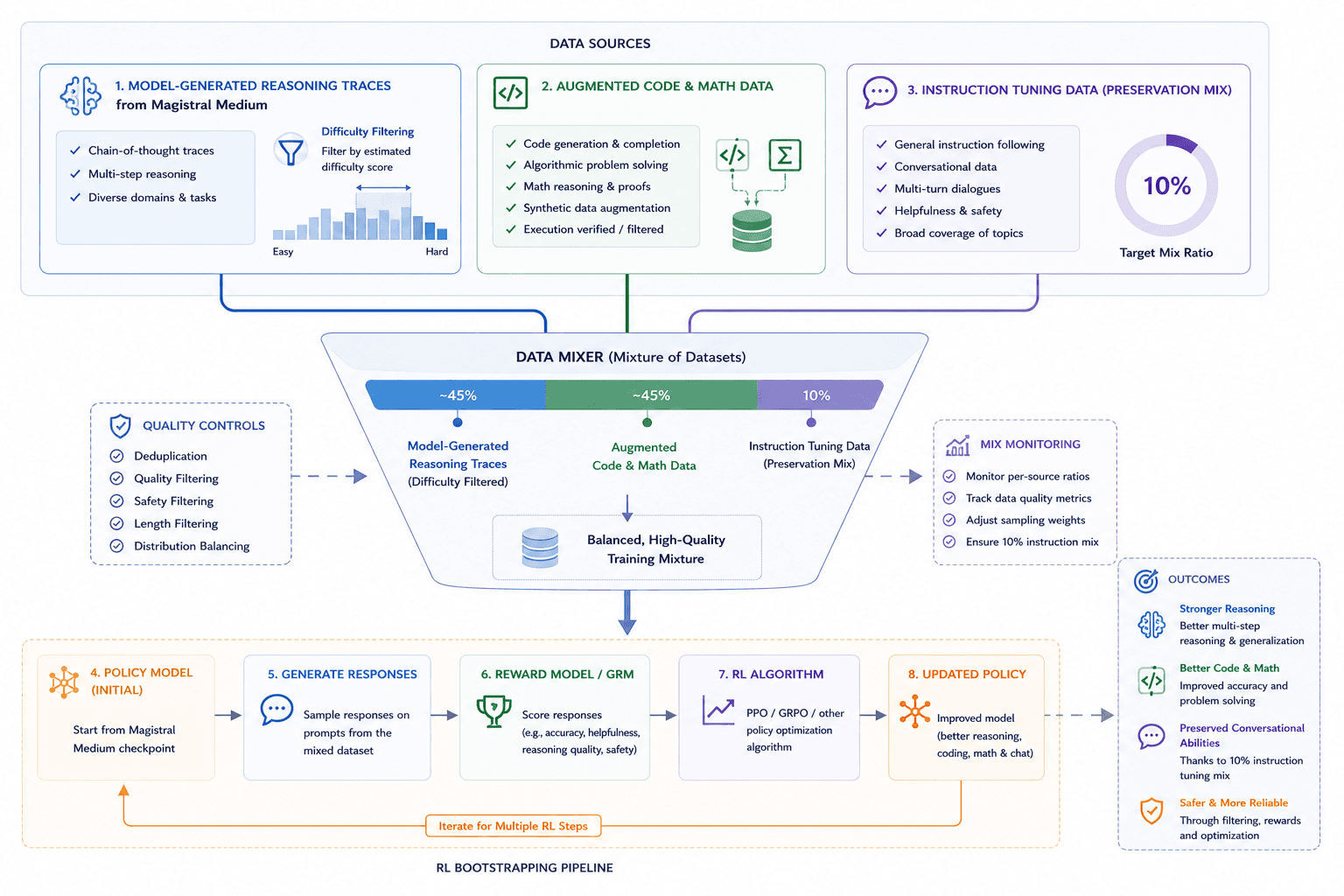
In early 2025, Mistral AI entered the frontier reasoning race with the release of Magistral, their first native reasoning model. Released in both an open-source version (Magistral Small, 24B parameters) and a more powerful enterprise version (Magistral Medium), it focuses heavily on domain-specific and multilingual chain-of-thought.
Mistral's approach contrasts with labs that rely entirely on distilling traces from larger, closed models. Magistral was presented as a reasoning-focused extension of Mistral's frontier model family, with reinforcement learning playing a central role in its post-training. To create the highly efficient Magistral Small, Mistral utilized a sophisticated bootstrapping pipeline: they generated reasoning traces from the Medium model, filtered them to maintain a mixed difficulty level, augmented the data with subsets from OpenThoughts and OpenR1, and blended in general instruction tuning data to ensure the model didn't lose its non-reasoning conversational skills. Perhaps its most unique feature is its native multilingual strategy; the model is trained to generate both reasoning traces and final responses in the user's requested language, showing that advanced reasoning behavior does not have to be exclusively English.
Limitations and Open Problems
The modern RL stack is powerful, but it is not a clean solution to reasoning. The first limitation is reward hacking. If a model finds a way to satisfy the reward without solving the real task, RL will reinforce the shortcut. This is especially dangerous when the evaluator is another model rather than a deterministic test.
The second limitation is benchmark overfitting. Math, coding, and reasoning benchmarks are useful because they provide clear feedback, but the same clarity also makes them easier to optimize against. A model can improve on a benchmark without gaining the same level of robustness in messy real-world tasks.
The third limitation is that verifiable rewards are unevenly distributed. Code, math, and structured outputs can often be checked automatically. Open-ended research, long-form writing, product planning, and scientific exploration are much harder to score. For these tasks, labs still rely on rubrics, model judges, human review, or indirect environment signals.
There is also a cost problem. Test-time compute can improve accuracy by letting the model sample, revise, and verify more aggressively, but it increases latency and serving cost. This makes the strongest reasoning modes harder to deploy everywhere.
Finally, hidden chain-of-thought creates an auditing problem. Many frontier systems may use long internal reasoning traces without exposing them directly. That can be good for safety and user experience, but it makes it harder for outsiders to inspect what the model actually learned from RL.
Conclusion
The case studies of OpenAI, DeepMind, Meta, DeepSeek, Mistral, Moonshot, and Anthropic suggest that frontier AI development has shifted from static pre-training alone toward a more interactive post-training stack. Verifiable rewards, online optimization, AI feedback, self-distillation, tool environments, and test-time compute now work together to shape how models reason.
Models no longer only memorize patterns from the internet. The strongest systems are trained and prompted to spend more computation checking math, debugging code, using tools, revising plans, and validating intermediate steps. Reinforcement Learning is not the only ingredient behind this shift, but it has become one of the central mechanisms turning raw language models into systems that can search, verify, and improve their own answers.
Bibliography
Foundations: RLHF, DPO, and AI Feedback
Ouyang et al., 2022. Training language models to follow instructions with human feedback. The InstructGPT paper that established the classic SFT -> reward model -> PPO alignment pipeline.
Bai et al., 2022. Constitutional AI: Harmlessness from AI Feedback. Anthropic's original RLAIF / Constitutional AI paper.
Rafailov et al., 2023. Direct Preference Optimization: Your Language Model is Secretly a Reward Model. The core DPO paper, useful for understanding offline preference optimization without explicit reward-model training.
Anthropic, 2023. Claude's Constitution. Public version of the principles used to guide Claude-style constitutional critique.
Anthropic, 2026. Claude's New Constitution. Updated public constitution and useful context for the shift from rule lists toward broader reason-based alignment.
Reasoning RL and Verifiable Rewards
OpenAI, 2024. Learning to Reason with LLMs. Primary OpenAI source for o1-style reasoning, RL training, and test-time compute framing.
DeepSeek-AI, 2025. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. Primary source for DeepSeek-R1, DeepSeek-R1-Zero, GRPO, and RLVR-style reasoning training.
Yue et al., 2025. Stable Reinforcement Learning for Efficient Reasoning. Introduces GRPO-$\lambda$ and discusses stabilizing length penalties during reasoning RL.
Moonshot AI, 2025. Kimi k1.5: Scaling Reinforcement Learning with LLMs. Primary source for Kimi's long-context RL and scaling approach.
Label Studio, 2025. Reinforcement Learning from Verifiable Rewards. Secondary explanation of RLVR; useful as an accessible conceptual overview, not as the main evidence source.
Frontier Model Case Studies
Meta AI, 2025. The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation. Primary source for Llama 4 post-training claims, including lightweight SFT, online RL, and DPO-style polishing.
Mistral AI, 2025. Magistral. Primary source for Mistral's reasoning model family, multilingual reasoning focus, and RL/post-training framing.
Google DeepMind, 2026. Accelerating Mathematical and Scientific Discovery with Gemini Deep Think. Primary DeepMind source for Gemini Deep Think and scientific reasoning claims.
Feng et al., 2026. Towards Autonomous Mathematics Research. Research paper describing Aletheia as a mathematics research agent built on Gemini Deep Think.
Feng et al., 2026. Aletheia tackles FirstProof autonomously. Follow-up evaluation of Aletheia on the FirstProof challenge.
Tehrani et al., 2026. Fine-Tuning GPT-5 for GPU Kernel Generation. Makora paper on RL fine-tuning for GPU kernel generation with verifiable rewards.
Makora, 2026. We RL'd GPT-5 to Write Better Kernels. Companion blog post for the Makora GPU-kernel RL work.
Useful Background and Secondary Reading
Decode the Future, 2024. RLHF explained. Accessible background on RLHF for readers who want a less technical introduction.
Le Wagon, 2025. OpenAI o1 and o3 explained: how thinking models work. Secondary overview of reasoning-model concepts; useful for intuition, but weaker than primary model/paper sources.
Accelerate your growth with
AI-led demos.
Launch your demo in 5 minutes!
Launch your demo in 5 minutes!

Don’t make your prospects wait–ever again. Scale your demos and increase your revenue.



" height="18.00002px" id="t3TUwhEsx" transform="translate(3 3.243)" width="18px"/></svg>)
" height="16.00002px" id="eM6xJX0fQ" transform="translate(3 4.243)" width="18px"/></svg>)
" height="23.33220463282985px" id="JFXEvpVdY" transform="translate(0.489 0.333)" width="23.02237881352199px"/></svg>)
" height="23.866674065589905px" id="K2XP5s9Up" transform="translate(0 0.133)" width="23.852008219791px"/></svg>)
 scale(1 1) translate(--0.05666666666666667, -0.2982222222222222)" id="Azbtm4YKc-3318398759-radial-gradient" r="1.0639022167225811"><stop offset="0" stop-color="rgba(0, 0, 0, 0)"/><stop offset="1" stop-color="rgb(0, 0, 0)"/></radialGradient></defs><path d="M 0 0 L 24 0 L 24 24 L 0 24 Z" fill="transparent" height="24px" id="Dan82935g" width="24px"/><path d="M 11.996 24 C 12.008 22.39 11.681 20.795 11.036 19.32 C 10.44 17.896 9.573 16.6 8.483 15.507 C 7.392 14.419 6.101 13.554 4.68 12.96 C 3.205 12.315 1.61 11.987 0 12 C 1.607 12.013 3.2 11.695 4.679 11.067 C 6.098 10.453 7.388 9.577 8.483 8.485 C 9.57 7.392 10.437 6.1 11.036 4.68 C 11.681 3.205 12.008 1.61 11.996 0 C 11.996 1.663 12.304 3.223 12.929 4.68 C 13.542 6.099 14.417 7.39 15.508 8.485 C 16.606 9.577 17.899 10.452 19.321 11.065 C 20.802 11.69 22.393 12.008 24 12 C 22.39 11.988 20.796 12.315 19.321 12.96 C 17.897 13.554 16.602 14.419 15.508 15.507 C 14.417 16.605 13.542 17.898 12.929 19.32 C 12.305 20.801 11.987 22.393 11.996 24 Z" fill="url(%23Azbtm4YKc-3318398759-radial-gradient)" height="24px" id="Azbtm4YKc" width="24px"/></svg>)
© 2026 Karumi. All rights reserved.